中文名称的文件下载
虽然在上一小节中,通过Spring MVC实现了文件下载功能,但此案例代码只适用于非中文名称的文件下载。当对中文名称的文件进行下载时,因为各个浏览器内部转码机制的不同,就会出现不同的乱码以及解析异常问题。例如在文件下载目录中添加一个名称为“壁纸.jpg”的文件,当通过浏览器下载该文件时,下载弹出窗口的显示如图1所示。
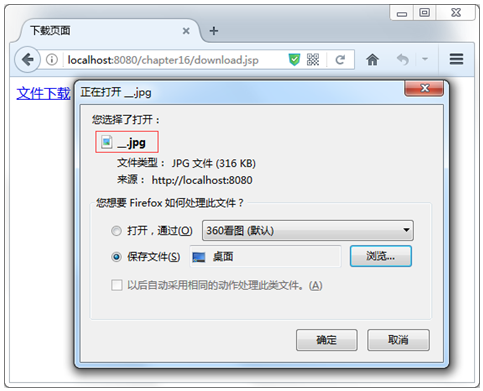
图1 火狐浏览器中文名文件下载信息
从图1可以看出,所要下载的文件名称并不是“壁纸.jpg”,而是“_.jpg”,这就表示中文文件名称出现了乱码。那么我们要如何解决这种乱码问题呢?
为了解决浏览器中文件下载时中文名称的乱码问题,可以在前端页面发送请求前先对中文名进行统一编码,然后在后台控制器类中对文件名称进行相应的转码。其具体实现步骤如下:
(1)在下载页面中对中文文件名编码。可以使用Servlet API中提供的URLEncoder类中的encoder(String s, String enc)方法将中文转为UTF-8编码。该方法中第一个参数表示需要转码的字符串,第二个参数表示编码格式。其具体实现方式如文件1所示。
文件1 download.jsp
1 <%@ page language="java" contentType="text/html; charset=UTF-8"
2 pageEncoding="UTF-8"%>
3 <%@page import="java.net.URLEncoder"%>
4 <!DOCTYPE HTML>
5 <html>
6 <head>
7 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
8 <title>下载页面</title>
9 </head>
10 <body>
11 <a href="${pageContext.request.contextPath }/download?filename=<%=
12 URLEncoder.encode("壁纸.jpg", "UTF-8")%>">
13 中文名称文件下载
14 </a>
15 </body>
16 </html>(2)修改控制器类FileUploadController中的fileDownload()方法,并增加对文件名进行编码的方法,其代码如下所示。
@RequestMapping("/download")
public ResponseEntity<byte[]> fileDownload(HttpServletRequest request,
String filename) throws Exception{
// 指定要下载的文件所在路径
String path = request.getServletContext().getRealPath("/upload/");
// 创建该文件对象
File file = new File(path+File.separator+filename);
// 对文件名编码,防止中文文件乱码
filename = this.getFilename(request, filename);
// 设置响应头
HttpHeaders headers = new HttpHeaders();
// 通知浏览器以下载的方式打开文件
headers.setContentDispositionFormData("attachment", filename);
// 定义以流的形式下载返回文件数据
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
// 使用Sring MVC框架的ResponseEntity对象封装返回下载数据
return new ResponseEntity<byte[]>(FileUtils.readFileToByteArray(file),
headers,HttpStatus.OK);
}
/**
* 根据浏览器的不同进行编码设置,返回编码后的文件名
*/
public String getFilename(HttpServletRequest request,
String filename) throws Exception {
// IE不同版本User-Agent中出现的关键词
String[] IEBrowserKeyWords = {"MSIE", "Trident", "Edge"};
// 获取请求头代理信息
String userAgent = request.getHeader("User-Agent");
for (String keyWord : IEBrowserKeyWords) {
if (userAgent.contains(keyWord)) {
//IE内核浏览器,统一为UTF-8编码显示
return URLEncoder.encode(filename, "UTF-8");
}
}
//火狐等其它浏览器统一为ISO-8859-1编码显示
return new String(filename.getBytes("UTF-8"), "ISO-8859-1");
} 在方法getFilename()中,由于IE浏览器在文件编码上与其它浏览器的方式不同,所以在中文编码设置上IE浏览器设置为UTF-8编码,而火狐等其它浏览器设置为ISO-8859-1编码。另外由于不同版本的IE浏览器,请求代理User-Agent中的关键字也略有不同,所以在判断IE浏览器时,需要特别注意User-Agent中的关键字。
再次进行中文名的文件下载测试,并在IE和火狐浏览器中分别单击文件下载链接后,两个浏览器的显示效果如图2所示。
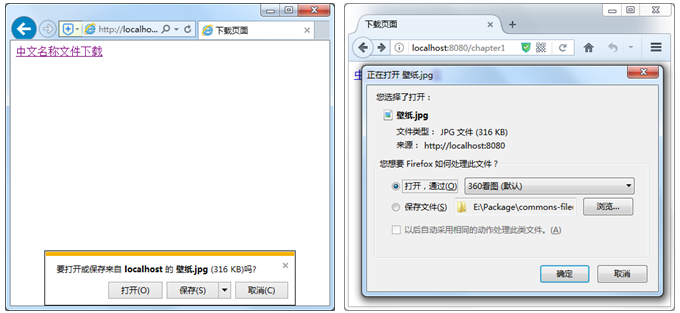
图2 IE和火狐中文名文件下载效果
从图2的显示效果可以看出,所下载的文件已在两个浏览器中正确显示出了中文名称。

隐藏目录