Hadoop的版本
Hadoop发行版本分为开源社区版和商业版,社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,例如比较著名的有Cloudera公司的CDH版本。
为了方便学习,本书采用开源社区版,而Hadoop自诞生以来,主要分为Hadoop1、Hadoop2、Hadoop3三个系列的多个版本。由于目前市场上最主流的是Hadoop2.x版本,因此,本书只针对Hadoop2.x版本进行相关介绍。
Hadoop2.x版本指的是第2代Hadoop,它是从Hadoop1.x发展而来的,并且相对于Hadoop1.x来说,有很多改进。下面我们从Hadoop1.x到Hadoop2.x发展的角度,对两版本进行讲解,如图1所示。
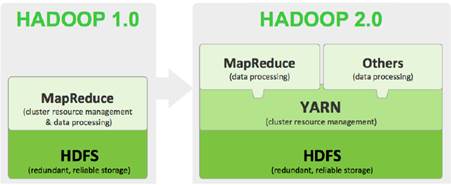
图1 Hadoop版本内核演变
通过图1可以看出,Hadoop1.0内核主要由分布式存储系统HDFS和分布式计算框架MapReduce两个系统组成,而Hadoop2.x版本主要新增了资源管理框架Yarn以及其他工作机制的改变。
在Hadoop1.x版本中,HDFS与MapReduce结构如图2和3所示。
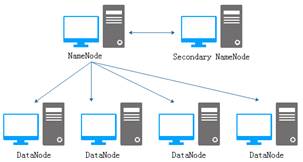
图2 HDFS组成结构
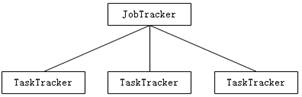
图3 MapReduce组成结构
从图2可以看出,HDFS由一个NameNode和多个DateNode组成,其中,DataNode负责存储数据,但是数据具体存储到哪个DataNode节点,则是由NameNode来决定的。
从图3可以看出MapReduce由一个JobTracker和多个TaskTracker组成,其中,MapReduce的主节点JobTracker只有一个,从节点TaskTracker有很多个,JobTracker与TaskTracker在MapReduce中的角色就像是项目经理与开发人员的关系,而JobTracker负责接收用户提交的计算任务、将计算任务分配给TaskTracker执行、跟踪,JobTracker同时监控TaskTracker的任务执行状况等。当然,TaskTracker只负责执行JobTracker分配的计算任务,正是由于这种机制,
Hadoop1.x架构中的HDFS和MapReduce存在以下缺陷:
(1)HDFS中的NameNode、SecondaryNode单点故障,风险是比较大的。其次,NameNode内存受限不好扩展,因为Hadoop1.x版本中的HDFS只有一个NameNode,并且要管理所有的DataNode。
(2)MapReduce中的JobTracker职责过多,访问压力太大,会影响系统稳定。除此之外,MapReduce难以支持除自身以外的框架,扩展性较低的不足。
Hadoop2.x版本为克服Hadoop1.x中的不足,对其架构进行了以下改进:
(1)Hadoop2.x可以同时启动多个NameNode,其中一个处于工作(Active)状态,另一个处于随时待命(Standby)状态,这种机制被称为Hadoop HA(Hadoop高可用),这样当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,自动切换到另一个NameNode持续提供服务。
(2)Hadoop2.x将JobTracker中的资源管理和作业控制分开,分别由ResourceManager(负责所有应用程序的资源分配)和ApplicationMaster(负责管理一个应用程序)实现,即引入了资源管理框架Yarn,它是一个通用的资源管理框架,可以为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架使用,如Tez、Spark、Storm,这种设计不仅能够增强不同计算模型和各种应用之间的交互,使集群资源得到高效利用,而且能更好地与企业中已经存在的计算结构集成在一起。
(3)Hadoop2.x中的MapReduce是运行在Yarn上的离线处理框架,它的运行环境不再由JobTracker和TaskTracker等服务组成,而是变成通用资源管理Yarn和作业控制进程ApplicationMaster,从而使MapReduce在速度上和可用性上都有很大的提高。
关于Hadoop2.0的HDFS、MapReduce以及Yarn的具体介绍,我们将在后续详细讲解,这里大家有个印象即可。

隐藏目录