案例——Shell定时采集数据到HDFS
在3.3.1节,我们对HDFS客户端命令行以及常用的命令进行了介绍,本节将通过采集数据文件脚本的案例来对前3.3.1节所学习的知识进行巩固。
服务器每天会产生大量日志数据,并且日志文件可能存在于每个应用程序指定的data目录中,在不使用其它工具的情况下,将服务器中的日志文件规范的存放在HDFS中。通过编写简单的shell脚本,用于每天自动采集服务器上的日志文件,并将海量的日志上传至HDFS中。由于文件上传时会消耗大量的服务器资源,为了减轻服务器的压力,可以避开高峰期,通常会在凌晨进行上传文件的操作。下面按照步骤实现Shell定时日志采集功能。
1.配置环境变量
首先在/export/data/logs目录下(如果目录不存在,则需要提前创建)使用vi命令创建upload2HDFS.sh脚本文件,在编写Shell脚本时,需要设置Java环境变量,即使我们当前虚拟机节点已经配置了Java环境变量,这样做是用来提高系统的可靠性,保障运行程序的机器在没有配置环境变量的情况下依然能够运行脚本。代码如下所示:
export JAVA_HOME=/export/servers/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH在配置完Java环境变量之后还需要配置Hadoop的环境变量,代码如下所示:
export HADOOP_HOME=/export/servers/hadoop-2.7.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH2.准备日志存放目录和待上传文件
为了让开发者便于控制上传文件的流程,可以在脚本中设置一个日志存放目录和待上传文件目录,若上传过程中发生错误只需要查看该目录就能知道文件的上传进度。添加相应代码如下所示:
#日志文件存放的目录
log_src_dir=/export/data/logs/log/#待上传文件存放的目录
log_toupload_dir=/export/data/logs/toupload/为了保证后续脚本文件能够正常执行,还需要在启动脚本前手动创建好这两个目录。
3.设置日志文件上传的路径
设置上传的HDFS目标路径,命名格式以时间结尾,并且输出打印信息。添加代码如下所示:
#设置日期
date1=`date -d last-day +%Y_%m_%d`#日志文件上传到hdfs的根路径
hdfs_root_dir=/data/clickLog/$date1/ #打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir4.实现文件上传
上传文件的过程就是遍历文件目录的过程,将文件首先移动到待上传目录,再从待上传目录中上传到HDFS中。添加代码如下所示:
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
date=`date +%Y_%m_%d_%H_%M_%S
\#将文件移动到待上传目录并重命名
echo "moving $log_src_dir$fileName to
$log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName
$log_toupload_dir"xxxxx_click_log_$fileName"$date
\#将待上传的文件path写入一个列表文件willDoing,
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >>
$log_toupload_dir"willDoing."$date
fi
done最后将文件从待上传目录传至HDFS中,具体代码如下所示:
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while
read line
do
\#打印信息
echo "toupload is in file:"$line
\#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
\#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名)
\#此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
\#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done如果在每天12点凌晨执行一次,我们可以使用Linux Crontab表达式执行定时任务。
0 0 * * * /shell/upload2HDFS.sh
上述crontab表达式是由6个参数决定,分别为分、时、日、月、周、命令组成,其中/shell/upload2HDFS.sh为shell脚本的绝对路径。由于crontab表达式并非本书重点,若想要深入学习的读者可以自行查阅资料学习。
5.执行程序展示运行结果
一般日志文件产生是由业务决定,例如每小时滚动一次或者日志文件大小达到1G时,就滚动一次,产生新的日志文件。为了避免每个日志文件过大导致上传效率低,可以采取在滚动后的文件名后添加一个标识的策略,例如access.log.x,x就是文件标识,它可以为序号、日期等自定义名称,该标识用于表示日志文件滚动过一次,滚动后的文件,新产生的数据将不再写入该文件中,当满足业务需求时,则文件可以被移动到待上传目录,如图1所示。
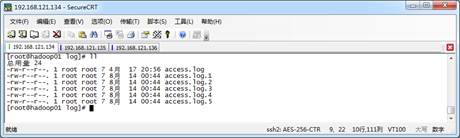
图1 滚动日志文件
从图1可以看出,为了模拟生产环境,在日志存放目录/export/data/logs/log/中,手动创建日志文件,access.log表示正在源源不断的产生日志的文件,access.log.1、access.log.2等表示已经滚动完毕的日志文件,即为待上传日志文件。
在upload2HDFS.sh文件路径下使用“sh upload2HDFS.sh”指令执行程序脚本,打印执行流程,如图2所示。
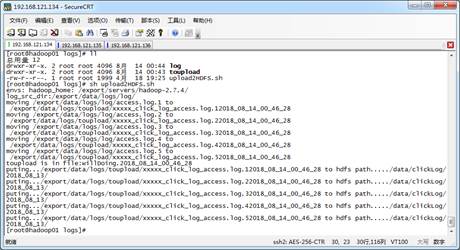
图2 运行脚本
从图2可以看出,首先将日志存放目录log中的日志文件移动到待上传toupload目录下,并根据业务需求重命名,然后脚本自动执行“hadoop put”上传命令,将待上传目录下的所有日志文件上传至HDFS中。通过HDFS Web界面可以看到,需要采集的日志文件已经按照日期分类,上传到HDFS中,如图3所示。
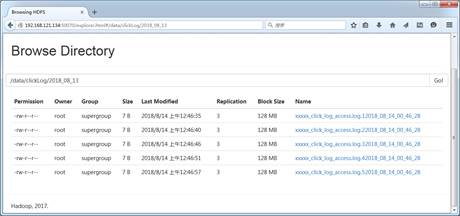
图3 日志采集文件
小提示:
Shell脚本语言并本章节的重点,读者只需要掌握本节案例的业务和思想,以及可以读懂简单的Shell脚本语言即可。

隐藏目录