Series
Pandas是一个基于NumPy的Python库,专门为了解决数据分析任务而创建的,它不仅纳入了大量的库和一些标准的数据模型,而且提供了高效操作大型数据集所需的工具,被广泛地应用到很多领域中,包括经济、统计、分析等学术和商业领域。
要想学好Pandas,前提是要对Pandas的数据结构有所了解。Pandas中有两个主要的数据结构:Series和DataFrame,其中Series是一维的数据结构,DataFrame是二维的、表格型的数据结构。
Series是一个类似于一维数组的对象,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。接下来,通过一张图来描述Series的结构,具体如图1所示。
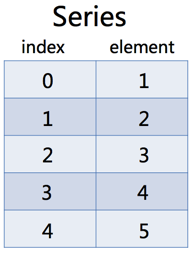
图1 Series对象结构示意图
图1展示的是Series结构表现形式,其索引位于左边,数据位于右边。
Pandas的Series类对象可以使用以下构造方法创建:
class pandas.Series(data = None,index = None,dtype = None,name = None,copy = False,
fastpath = False)上述构造方法中常用参数的含义如下:
(1) data:传入的数据,可以是ndarray、list等。
(2) index:索引,必须是唯一的,且与数据的长度相同。如果没有传入索引参数,则默认会自动创建一个从0~N的整数索引。
(3) dtype:数据的类型。
(4) copy:是否复制数据,默认为False。
接下来,通过传入一个列表来创建一个Series类对象,示例代码如下。
In [1]: import pandas as pd # 导入pandas库
ser_obj = pd.Series([1, 2, 3, 4, 5]) # 创建Series类对象
ser_obj
Out[1]:
0 1
1 2
2 3
3 4
4 5
dtype: int64上述代码中,使用构造方法创建了一个Series类对象。从输出结果可以看出,左边一列是索引,索引是从0开始递增的,右边一列是数据,数据的类型是根据传入的列表参数中元素的类型推断出来的,即int64。
当然,我们也可以在创建Series类对象的时候,为数据指定索引,示例代码如下。
In [2]: # 创建Series类对象,并指定索引
ser_obj = pd.Series([1, 2, 3, 4, 5],
index=['a', 'b', 'c', 'd', 'e'])
ser_obj
Out[2]:
a 1
b 2
c 3
d 4
e 5
dtype: int64除了使用列表构建Series类对象外,还可以使用dict进行构建,具体示例代码如下。
In [3]: year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data) # 创建Series类对象
ser_obj2
Out[3]:
2001 17.8
2002 20.1
2003 16.5
dtype: float64为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。例如,获取刚刚创建的ser_obj对象的索引和数据,代码如下。
In [4]: ser_obj.index # 获取ser_obj的索引
Out[4]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
In [5]: ser_obj.values # 获取ser_obj的数据
Out[5]: array([1, 2, 3, 4, 5], dtype=int64)上述示例中,通过index属性得到了一个Index类的对象,该对象是一个索引对象,后面会针对这个类型进行介绍。
当然,我们也可以直接使用索引来获取数据。例如,获取ser_obj对象中索引位置为3的元素,具体代码如下。
In [6]: ser_obj[3] # 获取位置索引3对应的数据
Out[6]: 4需要注意的是,索引和数据的对应关系仍保持在数组运算的结果中,也就是说,当某个索引对应的数据进行运算以后,其运算的结果会替换原数据,仍然与这个索引保持着对应的关系,具体示例代码如下。
In [7]: ser_obj * 2
Out[7]:
a 2
b 4
c 6
d 8
e 10
dtype: int64
隐藏目录