索引操作
Series类对象属于一维结构,它只有行索引,而DataFrame类对象属于二维结构,它同时拥有行索引和列索引。由于它们的结构有所不同,所以它们的索引操作也会有所不同。接下来,分别为大家介绍Series和DataFrame的相关索引操作,具体内容如下。
(一)Series的索引操作
Series有关索引的用法类似于NumPy数组的索引,只不过Series的索引值不只是整数。如果我们希望获取某个数据,既可以通过索引的位置来获取,也可以使用索引名称来获取,示例代码如下。
In [25]: import pandas as pd
ser_obj = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
ser_obj[2] # 使用索引位置获取数据
Out[25]: 3
In [26]: ser_obj['c'] # 使用索引名称获取数据
Out[26]: 3当然,Series也可以使用切片来获取数据。不过,如果使用的是位置索引进行切片,则切片结果和list切片类似,即包含起始位置但不包含结束位置;如果使用索引名称进行切片,则切片结果是包含结束位置的,示例代码如下。
In [27]: ser_obj[2: 4] # 使用位置索引进行切片
Out[27]:
c 3
d 4
dtype: int64
In [28]: ser_obj['c': 'e'] # 使用索引名称进行切片
Out[28]:
c 3
d 4
e 5
dtype: int64如果希望获取的是不连续的数据,则可以通过不连续索引来实现,具体示例代码如下。
In [29]: ser_obj[[0, 2, 4]] # 通过不连续位置索引获取数据集
Out[29]:
a 1
c 3
e 5
dtype: int64
In [30]: ser_obj[['a', 'c', 'd']] # 通过不连续索引名称获取数据集
Out[30]:
a 1
c 3
d 4
dtype: int64布尔型索引同样适用于Pandas,具体的用法跟数组的用法一样,将布尔型的数组索引作为模板筛选数据,返回与模板中True位置对应的元素,具体代码如下。
In [31]: ser_bool = ser_obj > 2 # 创建布尔型Series对象
ser_bool
Out[31]: a False
b False
c True
d True
e True
dtype: bool
In [32]: ser_obj[ser_bool] # 获取结果为True的数据
Out[32]:
c 3
d 4
e 5
dtype: int64(二)DataFrame的索引操作
DataFrame结构既包含行索引,也包含列索引。其中,行索引是通过index属性进行获取的,列索引是通过columns属性进行获取的,索引的结构如图1所示。
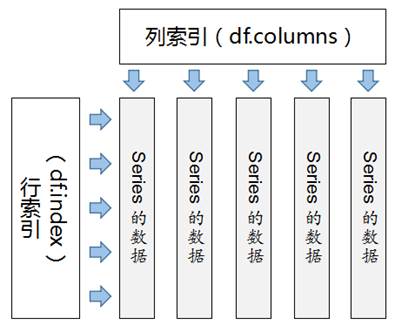
图1 DataFrame索引示意图
通过图1可以看出,DataFrame中每列的数据都是一个Series对象,我们可以使用列索引进行获取。例如,创建一个3行4列的DataFrame对象,并获取其中的1列数据,具体代码如下。
In [33]: arr = np.arange(12).reshape(3, 4)
# 创建DataFrame对象,并为其指定列索引
df_obj = pd.DataFrame(arr, columns=['a', 'b', 'c', 'd'])
df_obj
Out[33]:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
In [34]: df_obj['b'] # 获取b列的数据
Out[34]:
0 1
1 5
2 9
Name: b, dtype: int32
In [35]: type(df_obj['b'])
Out[35]: pandas.core.series.Series如果要从DataFrame中获取多个不连续的Series对象,则同样可以使用不连续索引进行实现,具体示例代码如下。
In [36]: df_obj[['b', 'd']] # 获取不连续的Series对象
Out[36]:
b d
0 1 3
1 5 7
2 9 11
In [37]: df_obj[:2] # 使用切片获取第0~1行的数据
Out[37]:
a b c d
0 0 1 2 3
1 4 5 6 7
# 使用多个切片先通过行索引获取第0~2行的数据,再通过不连续列索引获取第b、d列的数据
In [38]: df_obj[: 3][['b', 'd']]
Out[38]:
b d
0 1 3
1 5 7
2 9 11多学一招:使用Pandas提供的方法操作索引
虽然DataFrame操作索引能够满足基本数据查看请求,但是仍然不够灵活。为此,Pandas库中提供了操作索引的方法来访问数据,具体包括:
loc:基于标签索引(索引名称,如a、b等),用于按标签选取数据。当执行切片操作时,既包含起始索引,也包含结束索引。
iloc:基于位置索引(整数索引,从0到length-1),用于按位置选取数据。当执行切片操作时,只包含起始索引,不包含结束索引。
iloc方法主要使用整数来索引数据,而不能使用字符标签来索引数据。而loc方法恰恰相反,它只能使用字符标签来索引数据,而不能使用整数来索引数据。不过,当DataFrame对象的行索引或列索引使用的是整数时,则其就可以使用整数来索引。
假设,现在有一个DataFrame对象,具体代码如下。
In [39]: arr = np.arange(16).reshape(4, 4)
dataframe_obj = pd.DataFrame(arr, columns=['a', 'b', 'c', 'd'])
dataframe_obj
Out[39]:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15接下来,我们通过一段示例程序来演示如何使用上述方法来获取DataFrame中多列的数据,具体代码如下。
In [40]: dataframe_obj.loc[:, ["c", "a"]]
In [41]: dataframe_obj.iloc[:, [2, 0]]它们两个输出的结果一样,具体如下:
c a
0 2 0
1 6 4
2 10 8
3 14 12还可以通过loc方法和iloc方法使用花式索引来访问数据,具体代码如下。
In [43]: dataframe_obj.loc[1:2, ['b','c']]
In [44]: dataframe_obj.iloc[1:3, [1, 2]]它们两个输出的结果也是一样的,具体如下:
b c
1 5 6
2 9 10
隐藏目录