层次化索引的操作
有关层次化索引的常用操作包括选取子集操作、交换分层顺序和排序分层。其中,交换分层顺序是指外层索引与内层索引互换。接下来,我们来一一介绍这三种操作。
1. 选取子集操作
假设某商城在3月份统计了书籍的销售情况,并记录在如图1所示(部分)的表格中。
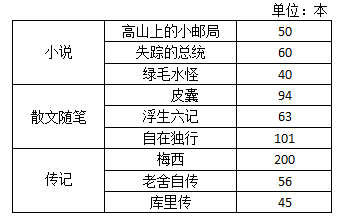
图1 某商城图书的月销售情况
图1的表格中,从左边数第1列的数据表示书籍的类别,第2列的数据表示书籍的名称,第3列的数据表示书籍的销售数量。其中,第1列内容作为外层索引使用,第2列内容作为内层索引使用。
如果商城管理员需要统计小说销售的情况,则可以从表中筛选出外层索引标签为小说的数据,具体代码如下。
In [73]: from pandas import Series
ser_obj = Series([50, 60, 40, 94, 63, 101, 200, 56, 45],
index=[['小说', '小说', '小说',
'散文随笔', '散文随笔', '散文随笔',
'传记', '传记', '传记'],
['高山上的小邮局', '失踪的总统', '绿毛水怪',
'皮囊', '浮生六记', '自在独行',
'梅西', '老舍自传', '库里传']])
ser_obj
Out[73]:
小说 高山上的小邮局 50
失踪的总统 60
绿毛水怪 40
散文随笔 皮囊 94
浮生六记 63
自在独行 101
传记 梅西 200
老舍自传 56
库里传 45
dtype: int64
In [74]: ser_obj['小说'] # 获取所有外层索引为“小说”的数据
Out[74]:
高山上的小邮局 50
失踪的总统 60
绿毛水怪 40
dtype: int64在上述代码中首先创建了一个具有层次化索引的Series对象ser_obj,然后通过指定外层索引名的方式,获取该索引名下所有的数据。
假设当前知道书籍的名称为“自在独行”,但类别和销售数量并不清楚,此时我们需要操作内层索引获取该书籍的类别与销售数量,示例代码如下。
In [75]: ser_obj[:,'自在独行'] # 获取内层索引对应的数据
Out[75]:
散文随笔 101上述代码中,操作内层索引的格式为“对象名[外层索引,内层索引]”,因为当前不知道该书籍属于哪一个类别,所以需要选中所有的外层索引,即用冒号表示选中所有外层索引,最后经过遍历查询返回该书籍的类别和销售数量。
2. 交换分层顺序
交换分层顺序是指交换外层索引和内层索引的位置。假设将图3-7中的表格进行交换分层操作,则交换前后的结果如图2所示。

图2 交换顺序
在Pandas中,交换分层顺序的操作可以使用swaplevel()方法来完成。接下来,我们通过swaplevel()方法来完成如图2所示的效果,来交换外层索引和内层索引的顺序,具体示例代码如下。
In [76]: ser_obj.swaplevel() # 交换外层索引与内层索引位置
Out[76]:
高山上的小邮局 小说 50
失踪的总统 小说 60
绿毛水怪 小说 40
皮囊 散文随笔 94
浮生六记 散文随笔 63
自在独行 散文随笔 101
梅西 传记 200
老舍自传 传记 56
库里传 传记 45
dtype: int64通过结果可以看出,外层索引和内层索引完成了交换,而且交换后数据没有发生任何变化。
3. 排序分层
要想按照分层索引对数据排序,则可以通过sort_index()方法实现,该方法的语法格式如下:
sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',
na_position ='last',sort_remaining = True,by = None)上述方法的部分参数含义如下:
(1) by:表示按指定的值排序。
(2) ascending:布尔值,表示是否升序排列,默认为True。
在使用sort_index()方法排序时,会优先选择按外层索引进行排序,然后再按照内层索引进行排序。假设有一个具有两层索引的表格,它按照索引排序前与排序后的效果如图3所示。
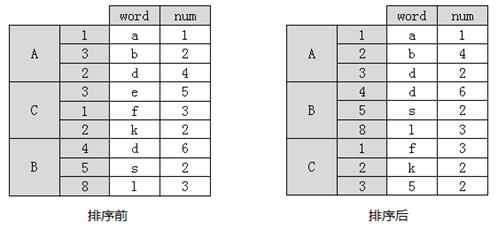
图3 按外层索引排序
接下来,我们通过一段示例程序来演示如何对多层索引结构进行排序,具体内容如下。
首先,我们使用DataFrame类创建一个与图3-9左侧表格结构相同的对象,具体示例代码如下。
In [77]: from pandas import DataFrame
df_obj = DataFrame({'word':['a','b','d','e','f','k','d','s','l'],
'num':[1, 2, 4, 5, 3, 2, 6, 2, 3]},
index=[['A', 'A', 'A', 'C', 'C', 'C', 'B', 'B', 'B'],
[1, 3, 2, 3, 1, 2, 4, 5, 8]])
df_obj
Out[77]:
word num
A 1 a 1
3 b 2
2 d 4
C 3 e 5
1 f 3
2 k 2
B 4 d 6
5 s 2
8 l 3然后,调用sort_index()方法按照索引对df_obj进行排序,具体代码如下:
In [78]: df_obj.sort_index() # 按索引排序
Out[78]:
word num
A 1 a 1
2 d 4
3 b 2
B 4 d 6
5 s 2
8 l 3
C 1 f 3
2 k 2
3 e 5通过比较排序前和排序后输出的结果可以看出,外层索引按字母表顺序进行排列,内层索引按照从小到大的顺序进行升序排序,且每行对应的数据均随着索引的位置而发生移动。
如果希望按照num一列进行排序,则可以在调用sort_index()方法时传入by参数,示例代码如下:
# 按num列降序排列
In [79]: df_obj.sort_index(by = ['num'], ascending = False)
Out[79]:
word num
B 4 d 6
C 3 e 5
A 2 d 4
C 1 f 3
B 8 l 3
A 3 b 2
C 2 k 2
B 5 s 2
A 1 a 1
隐藏目录