读写文本文件
在对数据进行分析时,通常不会将需要分析的数据直接写入到程序中,这样不仅造成程序代码臃肿,而且可用率很低。常用的方法是将需要分析的数据存储到本地中,之后再对存储文件进行读取。针对不同的存储文件,Pandas读取数据的方式是不同的。
CSV文件是一种纯文本文件,可以使用任何文本编辑器进行编辑,它支持追加模式,节省内存开销。因为CSV文件具有诸多的优点,所以在很多时候会将数据保存到CSV文件中。
Pandas中提供了read_csv()函数与to_csv()方法,分别用于读取CSV文件和写入CSV文件,关于他们的具体介绍如下:
1. 通过to_csv()方法将数据写入CSV文件
to_csv()方法的功能是将数据写入到CSV文件中,其语法格式如下:
to_csv(path_or_buf=None,sep=',',na_rep='',float_format=None,
columns=None,header=True, index=True, index_label=None, mode='w',
encoding=None, compression=None,quoting=None,quotechar='"',
line_terminator='\n',chunksize=None, tupleize_cols=None,
date_format=None, doublequote=True, escapechar=None, decimal='.')上述方法中常用参数表示的含义如下:
(1) path_or_buf:文件路径。
(2) index:布尔值,默认为True。若设为False,则将不会显示索引。
(3) sep:分隔符,默认用“.”隔开。
如果指定的路径下文件不存在,则会新建一个文件来保存数据;如果文件已经存在,则会将文件中的内容进行覆盖。
为了能够让大家更好地理解to_csv()方法的使用,接下来,通过一段示例代码来演示如何将DataFrame对象中的数据写入到CSV文件中,具体代码如下。
In [80]: import pandas as pd
df = pd.DataFrame({'one_name':[1,2,3],'two_name':[4,5,6]})
# 将df对象写入到csv格式的文件中
df.to_csv(r'E:\数据分析\itcast.csv', index=False)
'写入完毕'
Out[80]: '写入完毕'上述示例中,创建了一个3行2列的df对象,然后通过to_csv()方法将df对象中的数据写入到E盘指定的位置。为了提示程序执行结束,可以在末尾打印一句话“写入完毕”,提示程序是否执行完成。
代码执行成功后,会在E盘目录中生成一个名为“itcast.csv”的文件。使用Excel工具打开itcast.csv文件,可以看到写入的数据如图1所示。
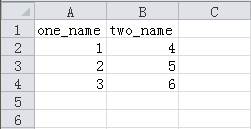
图1 itcast.csv文件
2. 通过read_csv()函数读取CSV文件的数据
read_csv()函数的作用是将CSV文件的数据读取出来,转换成DataFrame对象展示。read_csv()函数的语法格式如下。
read_csv(filepath_or_buffer,sep=',', delimiter=None, header='infer', names=None,
index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None ...)上述函数中常用参数表示的含义如下:
(1) filepath_or_buffer:表示文件路径,可以为URL字符串。
(2) sep:指定使用的分隔符,如果不指定默认用“,”分隔。
(3) header:指定行数用来作为列名,如果读取的文件中没有列名,则默认为0,否则设置为None。需要注意的是,当skip_blank_lines = True时,这个参数忽略注释行和空行,当明确设定header=0时,就会替换掉原来存在的列名。
(4) names:用于结果的列名列表。如果文件不包含标题行,则应该将该参数设置为None。
(5) index_col:用作行索引的列编号或者列名,如果给定一个序列,则表示有多个行索引。
需要注意的是,在读取文件时,如果传入的是文件的路径,而不是文件名,则会出现报错,具体的解决方法是先切换到该文件的目录下,使用os模块获取该文件的文件名。
接下来,使用read_csv()函数将存储在E盘目录下 “itcast.csv”文件的内容读取出来,示例代码如下。
In [81]: import pandas as pd
file = open(r"E:\数据分析\itcast.csv")
# 读取指定目录下的csv格式的文件
file_data = pd.read_csv(file)
file_data
Out[81]:
one_name two_name
0 1 4
1 2 5
2 3 6Text格式的文件也是比较常见的存储数据的方式,后缀名为".txt",它与上面提到的CSV文件都属于文本文件。如果希望读取Text文件,既可以用前面提到的read_csv()函数,也可以使用read_table()函数。
假设现在有一个名称为“itcast.txt”的Text文件,打开文件后的内容如图2所示。
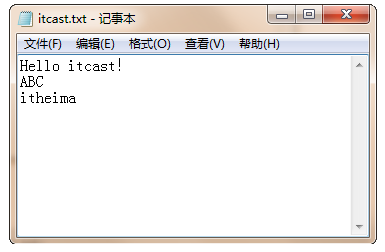
图2 打开itcast.txt文件
接下来,使用read_table()函数读取itcast.txt文件中的数据,具体代码如下。
In [82]: import pandas as pd
file = open(r'E:\数据分析\itcast.txt')
data = pd.read_table(file)
data
Out[82]:
Hello itcast!
0 ABC
1 itheima上述示例中,调用read_table()函数读取itcast.txt文件,默认读取时以“\t”为分隔符,并将数据转换成data对象展示。由于文本文件中只有三行内容,所以默认将文件中的第一行内容作为列索引。
注意:
read_csv()与read_table()函数的区别在于使用的分隔符不同,前者使用“,”作为分隔符,而后者使用“\t”作为分隔符。

隐藏目录