哑变量处理类别型数据
哑变量又称虚拟变量、名义变量,从名称上看就知道,它是人为虚设的变量,用来反映某个变量的不同类别。使用哑变量处理类别转换,事实上就是将分类变量转换为哑变量矩阵或指标矩阵,矩阵的值通常用“0”或“1”表示。
假设变量“职业”的取值分别为司机、学生、导游、工人、教师共5种选项,如果使用哑变量表示,则可以分别表示为col_司机(1=司机/0=非司机)、col_学生(1=学生/0=非学生)、col_导游(1=导游/0=非导游)、col_工人(1=工人/0=非工人)、col_教师(1=教师/0=非教师),使用哑变量处理后的结果,如图1所示。
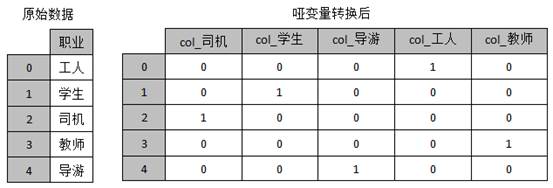
图1 经过哑变量
在Pandas中,可以使用get_dummies()函数对类别特征进行哑变量处理,其语法格式如下:
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False,columns=None,
sparse=False, drop_first=False, dtype=None)上述函数中常用参数表示的含义如下:
(1) data:可接收数组、DataFrame或Series对象,表示哑变量处理的数据。
(2) prefix:表示列名的前缀,默认为None。
(3) prefix_sep:用于附加前缀作为分隔符使用,默认为“_”。
(4) dummy_na:表示是否为NaN值添加一列,默认为False。
(5) columns:表示DataFrame要编码的列名,默认为None。
(6) sparse:表示虚拟列是否是稀疏的,默认为False。
(7) drop_first:是否通过从k个分类级别中删除第一个级来获得k-1个分类级别,默认为False。
接下来,通过一个示例来演示通过get_dummies()函数进行哑变量处理的效果,具体代码如下:
In [45]: import pandas as pd
df1 = pd.DataFrame({'职业': ['工人', '学生', '司机', '教师', '导游']})
pd.get_dummies(df1, prefix=['col_']) # 哑变量处理
Out[45]:
col_司机 col_学生 col_导游 col_工人 col_教师
0 0 0 0 1 0
1 0 1 0 0 0
2 1 0 0 0 0
3 0 0 0 0 1
4 0 0 1 0 0上述示例中,创建了一个DataFrame对象df1,接着调用了get_dummies()函数进行哑变量处理,将数据变成哑变量矩阵,每个特征数据(如学生)为单独一列,通过prefix参数给每个列名添加了前缀“col1”,并用“_”进行连接,使其变为col1_司机、col1_学生、col1_导游、col1_工人、col1_教师。
通过输出结果可以看出,一旦原始数据中的值在矩阵中出现,就会以数值1表现出来,其余则以0显示。

隐藏目录