词形归一化
在英文中,一个单词常常是另一个单词的变种,比如looking是look这个单词的一般进行式,looked为一般过去式,这些都会影响语料库学习的准确度。一般在信息检索和文本挖掘时,需要对一个词的不同形态进行规范化,以提高文本处理的效率。
词形规范化过程主要包括两种:词干(由词根与词缀构成的,一个词除去词尾的部分)提取和词形还原,它们的相关说明如下:
- 词干提取(stemming):是指删除不影响词性的词缀(包括前缀、后缀、中缀、环缀),得到单词词干的过程。例如:
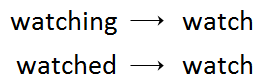
- 词形还原(lemmatization):与词干提取相关,不同的是能够捕捉基于词根的规范单词形式。例如:
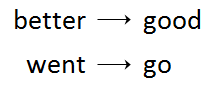
对于词干提取来说,nltk.stem模块中提供了多种词干提取器,目前最受欢迎的就是波特词干提取器,它是基于波特词干算法来提取词干的,这些算法都集中在PorterStemmer类中。下面是基于PorterStemmer类提取词干的示例,具体如下。
In [9]: # 导入nltk.stem模块的波特词干提取器
from nltk.stem.porter import PorterStemmer
# 按照波特算法提取词干
porter_stem = PorterStemmer()
porter_stem.stem('watched')
Out[9]: 'watch'
In [10]: porter_stem.stem('watching')
Out[10]: 'watch'还可以用兰卡斯特词干提取器提取,它是一个迭代提取器,具有超过120条规则来具体说明如何删除或替换词缀以获得词干。兰卡斯特词干提取器基于兰卡斯特词干算法,这些算法都集中在LancasterStemmer类中。以下代码显示了LancasterStemmer类提取词干的用法,示例代码如下。
In [11]: from nltk.stem.lancaster import LancasterStemmer
lancaster_stem = LancasterStemmer()
# 按照兰卡斯特算法提取词干
lancaster_stem.stem('jumped')
Out[11]: 'jump'
In [12]: lancaster_stem.stem('jumping')
Out[12]: 'jump'还有一些其它的词干器,比如SnowballStemmer,它除了支持英文以外,还支持其它13种不同的语言,用法示例如下。
In [13]: from nltk.stem import SnowballStemmer
snowball_stem = SnowballStemmer('english')
snowball_stem.stem('listened')
Out[13]: 'listen'
In [14]: snowball_stem.stem('listening')
Out[14]: 'listen'注意,在创建SnowballStemmer实例时,必须要传入一个表示语言的字符串给language参数。
词形还原的过程与词干提取非常相似,就是去除词缀以获得单词的基本形式,不过,这个基本形式称为根词,而不是词干。根词始终存在于词典中,词干不一定是标准的单词,它可能不存在于词典中。NLTK库中提供了一个强大的还原模块,它使用WordNetLemmatizer类来获得根词,使用前需要确保已经下载了wordnet语料库。
WordNetLemmatizer类里面提供了一个lemmatize()方法,该方法通过比对wordnet语料库,并采用递归技术删除词缀,直至在词汇网络中找到匹配项,最终返回输入词的基本形式。如果没有找到匹配项,则直接返回输入词,不做任何变化。
下面是一个基于WordNetLemmatizer的词形还原示例,代码如下。
In [15]: from nltk.stem import WordNetLemmatizer
# 创建WordNetLemmatizer对象
wordnet_lem = WordNetLemmatizer()
# 还原books单词的基本形式
wordnet_lem.lemmatize('books')
Out[15]: 'book'
In [16]: wordnet_lem.lemmatize('went')
Out[16]: 'went'
In [17]: wordnet_lem.lemmatize('did')
Out[17]: 'did'从输出结果可以看出,复数形式的单词books已经还原为book,不过单词went与did都没有还原,这主要是因为它们有多种词性,例如,went作为动词使用时,代表单词go的过去式,但是作为名词使用的话,它表示的是人名文特。
为了解决这个问题,可以直接在词形还原时指定词性,也就是说在调用lemmatize()方法时将词性传入pos参数,示例代码如下。
In [18]: # 指定went的词性为动词
wordnet_lem.lemmatize('went', pos='v')
Out[18]: 'go'
In [19]: wordnet_lem.lemmatize('did', pos='v')
Out[19]: 'do'从输出结果中可以看出,所有过去式的单词已经被还原为基本形式了。

隐藏目录