Hive数据模型
Hive中所有的数据都存储在HDFS中,它包含数据库(Database)、表(Table)、分区表(Partition)和桶表(Bucket)四种数据类型,其模型如图1所示。
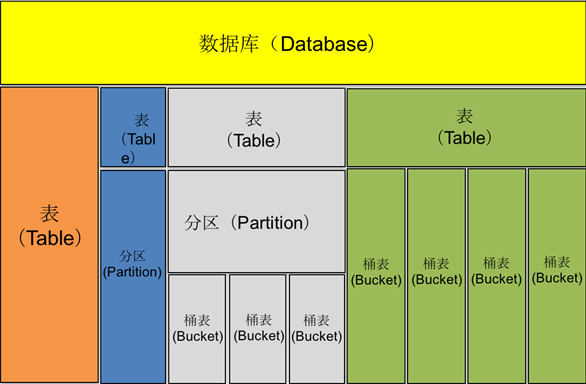
图1 Hive的数据模型
下面针对Hive数据模型中的数据类型进行介绍。
(1)数据库:相当于关系型数据库中的命名空间(namespace),它的作用是将用户和数据库的应用隔离到不同的数据库或者模式中。
(2)表:Hive的表在逻辑上由存储的数据和描述表格数据形式的相关元数据组成。表存储的数据存放在分布式文件系统里,例如HDFS。Hive中的表分为两种类型,一种叫做内部表,这种表的数据存储在Hive数据仓库中,一种叫做外部表,这种表的数据可以存放在Hive数据仓库外的分布式文件系统中,也可以存储在Hive数据仓库中。值得一提的是,Hive数据仓库也就是HDFS中的一个目录,这个目录是Hive数据存储的默认路径,它可以在Hive的配置文件中配置,最终也会存放到元数据库中。
(3)分区:分区的概念是根据“分区列”的值对表的数据进行粗略划分的机制,在Hive存储上的体现就是在表的主目录(Hive的表实际显示就是一个文件夹)下的一个子目录,这个子目录的名字就是我们定义的分区列的名字。
使用分区是为了加快数据查询速度设计的,例如,现在有个日志文件,文件中的每条记录都带有时间戳。如果根据时间来分区,那么同一天的数据将会被分到同一个分区中。这样的话,如果查询每一天或某几天的数据就会变得很高效,因为只需要扫描对应分区中的文件即可。
注意:分区列不是表里的某个字段,而是独立的列,我们根据这个列查询存储表中的数据文件。
(4)桶表:简单来说,桶表就是把“大表”分成了“小表”。把表或者分区组织成桶表的目的主要是为了获得更高的查询效率,尤其是抽样查询更加便捷。桶表是Hive数据模型的最小单元,数据加载到桶表时,会对字段的值进行哈希取值,然后除以桶个数得到余数进行分桶,保证每个桶中都有数据,在物理上,每个桶表就是表或分区的一个文件。

隐藏目录