Hive内部表操作
在7.6.1小节中,完成创建数据仓库后,使用命令“use itcast”切换到新创建的itcast数据仓库,接下来就可以在数据库中进行数据表的创建、修改等相关操作。其中Hive中创建表的基本语法格式如下所示:
1创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]2复制表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name [LOCATION hdfs_path];上述语法格式中,声明了两种创建Hive表的语法格式:第一种,用于创建自定义的Hive数据表;第二种,用于在已有表的基础上复制新的表,这种语法只会复制表的结构,不会复制表中的数据。另外,如果创建的表名已经存在,与创建数据仓库一样会抛出异常,用户可以使用“IF NOT EXISTS”选项来忽略这个异常。
需要说明的是,上述创建Hive数据表的语法中,[]中包含的内容为可选项,在创建表的同时可以声明很多约束信息,其中重要参数的说明如下:
- TEMPORARY:创建一个临时表,该表仅对当前会话可见。临时表数据将存储在用户的暂存目录中,并在会话结束时删除。
- EXTERNAL:创建一个外部表,这时就需要指定数据文件的实际路径( hdfs_path)。忽略EXTERNAL选项时,默认创建一个内部表,Hive会将数据文件移动到数据仓库所在的文件夹下,而创建外部表时,仅记录数据所在的路径,并不会移动数据文件的位置。
- PARTITIONED BY:创建带有分区的表,一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在于表文件夹的目录下,表和列名不区分大小写,分区是以字段的形式在表结构中存在,通过Describe table_name命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
- CLUSTERED BY:对于每个表或者分区,可以进一步将若干个列放入一个桶中,分桶的目的一是为了获得更高的查询效率,二是使取样更高效。
- SORTED BY:对列排序的选项,可以提高查询性能。
- ROW FORMAT:行格式是指一行中的字段存储格式,Hive默认采用‘\001’作为分隔符(Linux系统下使用Vi编辑器输入Ctrl+V和Ctrl+A所组成的字符,记作^A),它通常不会出现在我们的数据文件中,因此在加载数据时,需要选用合适的字符作为分隔符来映射字段,否则表中数据为NULL。在编写ROW FORMAT选项参数时,可以选用以下指定规则:
row_format
: DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char]
| SERDE serde_name
[WITH SERDEPROPERTIES
(property_name=property_value,
property_name=property_value, ...)
]- STORED AS:指文件存储格式,默认指定Textfile格式,导入数据时会直接把数据文件拷贝到HDFS上不进行处理,数据不压缩,解析开销较大。在编写STORED AS选项参数时,可以选用以下指定规则:
file_format:
: SEQUENCEFILE
| TEXTFILE
| RCFILE
| ORC
| PARQUET
| AVRO
| JSONFILE
| INPUTFORMAT input_format_classname OUTPUTFORMAT
output_format_classname- LOCATION:指需要映射为对应Hive数据仓库表的数据文件在HDFS上的实际路径。
在对创建Hive数据表的语法格式有所了解后,接下来,就通过几个示例来演示说明Hive数据表的具体创建。
(1)针对基本类型建表
首先,在hadoop01机器的/export/data目录下创建hivedata目录,在该文件夹下创建user.txt文件,并添加如下数据内容如下:
1,allen,18
2,tom,23
3,jerry,28针对hivedata目录准备的结构化文件user.txt先创建一个内部表t_user,具体示例如下:
hive> create table t_user(id int,name string,age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';上述建表语句中,根据结构化文件user.txt的具体内容及信息创建了具体有id、name、age字段的内部表t_user,同时使用ROW FORMAT选项指定了映射文件的分隔符为“,”。创建成功后,通过WEB UI界面打开Hive内部表所在HDFS路径(内部表默认/user/hive/warehouse/itcast.db/t_user)进行查看,如图1所示。
图1 Hive表所在位置
从图1可以看出,在对应的itcast数据库下创建了定义的t_user数据表,但是当前表文件夹内为空,这是因为执行上述指令,将结构化文件移动到内部表所在文件夹下后,通过远程连接访问itcast数据仓库下的t_user表信息,结果如图2所示:
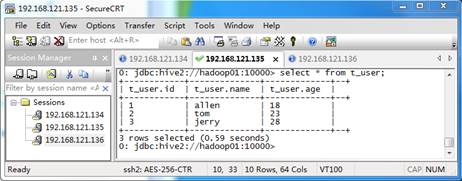
图2 t_user表信息
从图2可以看出,结构化数据与表映射成功。针对基本数据类型,我们非常容易选择分隔符字段。但是,当针对复杂数据类型时,就需要考虑其他分隔符字段选项了。
(2)针对复杂类型数据建表
例如,现有结构化数据文件student.txt,文件内容如下所示。
1,zhangsan,唱歌:非常喜欢-跳舞:喜欢-游泳:一般般
2,lisi,打游戏:非常喜欢-篮球:不喜欢通过对student.txt文件内容分析得出,可以设计为3列字段,即编号、姓名、兴趣,其中编号可以为int类型,姓名可以为string类型,而兴趣列还需要进一步分隔为Map类型,因此在创建student.txt文件对应的内部表语句如下所示:
hive> create table t_student(id int,name string,hobby map<string,string>)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';上述建表语句中,通过对student.txt文件结构化文件的分析,先通过逗号“,”对多个字段fields进行分隔;接着,针对hobby字段列,通过横线“-”进行集合列分隔;最后,再针对每一个爱好,通过冒号“:”进行分隔为最终的“key:value”形式。执行上述建表语句后,就会在默认的/user/hive/warehouse/itcast.db文件夹下生成一个t_student文件夹。此时,还必须将前面的结构化文件student.txt上传到该文件夹下进行映射,才能生成对应的内部表数据,上传完成后再次查询生成的t_student表信息,如图3所示。
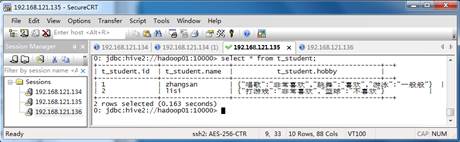
图3 t_student表信息
通过上面的两个创建Hive表的案例可知,在创建Hive内部表时,必须注意以下两点:第一,建表语句必须根据结构化文件内容和需求,指定匹配的分隔符;第二,在创建Hive内部表时,执行建表语句后,还必须将结构化文件移动到对应的内部表文件夹下进行映射,才能够生成对应的数据。

隐藏目录