创建进程
多道程序环境中,需要创建进程的情况通常有四种:用户登录、作业调度、用户请求和应用请求。当一个程序执行时,它可能需要申请一些资源,比如打开某个文件,请求某项服务等,根据之前讲解的知识,遇到这种情况,进程会进入睡眠态,并放弃占用的CPU。若要申请的资源与之后的操作并不冲突,为了保障当前进程的持续执行(走完当前的时间片),此时可以在内存中,再创建一个进程,让新的进程代替原进程执行资源申请的工作。
1、 创建一个进程
Linux使用fork()函数创建进程。fork函数是Linux多任务系统实现的基础,它包含在函数库unistd.h中,其函数声明如下:
pid_t fork(void);调用fork()函数创建的进程称为子进程,调用fork()函数的进程为父进程。调用fork()函数后,系统会创建一个与原进程近乎相同的进程,之后父子进程都继续往下执行,如图1所示。
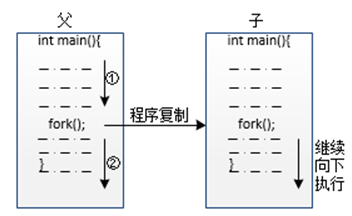
图1 fork()函数创建子进程
一般情况下,C风格的函数只能有一个返回值,但fork()函数非常特殊,“它”能返回两个值。当然,并不是因为fork()函数的构造特殊,而是因为,fork()函数调用后,若子进程创建成功,那么原程序会被复制,也就有了两个fork()函数。子进程创建成功后,父进程中的fork()函数会获得子进程的pid,子进程中的fork()函数返回0;若子进程创建失败,原程序不会被复制,父进程的fork()函数返回-1。
下面通过一个案例,来展示fork()函数的使用方法。
案例1:使用fork()函数创建一个进程,进程创建成功后使父进程与子进程分别执行不同的功能。
案例实现如下:
test_fork.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 int main()
5 {
6 pid_t pid;
7 pid=fork(); //调用fork()函数创建子进程
8 if(pid==-1) //创建失败
9 {
10 perror("fork error");
11 exit(1); //退出进程,指定返回值1
12 }
13 else if(pid>0) //父进程
14 {
15 printf("parent process,pid=%d,ppid=%d\n",getpid(),getppid());
16 }
17 else if(pid==0) //子进程
18 {
19 printf("child process,pid=%d,ppid=%d\n",getpid(),getppid());
20 }
21 printf("........finish..........\n");
22 return 0;
23 }编译程序文件test_fork.c,指定可执行文件名为test_fork,在程序所在目录下执行test_fork,程序的执行结果如下所示:
[itheima@localhost ~]$ ./test_fork
parent process,pid=3336,ppid=2707
........finish..........
child process,pid=3337,ppid=3336
........finish..........根据执行结果可以得知,父进程的pid为3336,子进程的pid为3337,在父进程pid 的基础上加1;父进程也有父进程,其ppid为2207。子进程创建成功,且父子进程分别执行了不同的功能。
读者可能会有疑惑:为什么代码21行的printf()函数打印了两次finish呢?其实由图6-3就能看出,调用过fork()函数之后,程序变为了两份,每份程序在结束前,都打印了一次finish。而案例1中多线程实现多任务的实质,是父子进程根据两个程序中fork()函数不同的返回值,分别执行不同的分支,因此程序的执行结果中finish被打印了两次。
思考1:
多次执行文件test_fork,发现这种情况:child process后输出的ppid不等于parent process,而等于1。这是什么原因?
2、 创建多个进程
计算机能实现的功能是很复杂的,可能在一个进程执行的过程中,需要创建多个线程,这些进程又需分别申请不同的资源,或执行其它操作。假设现在要求进程创建5个子进程,很容易便会想到使用循环:将fork()函数放在循环结构中,循环5次,就能创建5个进程。那么实际情况是不是这样呢?我们来验证一下。
对案例1中的代码进行修改,使用以下代码替代案例1第7行的代码:
int i;
for(i=0;i<5;i++)
{
pid=fork();
}再次编译源程序,在命令窗口执行可执行文件,按下回车,执行结果将被输出。按照预期,执行结果中应打印6条进程信息,但实际输出信息的数量远远超过6条。对代码进行分析:当第一次循环结束时,父进程创建了一个子进程,如图2所示。
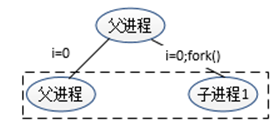
图2 第一次循环
前面小节中讲到:每次调用fork()函数,系统会复制原程序。那么此时系统中应有两份test_fork文件;之后两个test_fork文件都继续向下执行,也就是父进程与其创建的子进程1,都会进行第二次循环,那么产生的进程如图3所示:

图3 第二次循环
按照这种规律,每一次循环后,进程的总数应为当前进程数量的两倍,5次循环之后,实际进程的数量应为25,也就是32个,这显然与设想不符。
结合原设想,分析循环过程,可以发现,我们本来只希望父进程可以创建新进程,但实际执行时,子进程也会创建进程,因此,应该在for循环中添加一个判断:若当前进程不是父进程,那么就跳出循环。
按照这个思路,再次设计代码,为了使输出结果格式清晰,案例2中删除打印finish的printf()。代码实现如下。
案例2:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int main()
6 {
7 pid_t pid;
8 int i;
9 for(i=0;i<5;i++){ //循环创建进程
10 if((pid=fork())==0) //若当前进程为子进程,便跳出循环
11 break;
12 }
13 if(pid==-1){
14 perror("fork error");
15 exit(1);
16 }
17 else if(pid>0){ //父进程
18 printf("parent process:pid=%d\n",getpid());
19 }
20 else if(pid==0){ //子进程
21 printf("I am child=%d,pid=%d\n",i+1,getpid());
22 }
23 return 0;
24 }编译程序,执行可执行文件,执行结果如下:
I am child=4,pid=2945
parent process:pid=2941
I am child=1,pid=2942
I am child=5,pid=2946
[itheima@localhost ~]$ I am child=3,pid=2944
I am child=2,pid=2943
|(终端提示符)观察程序执行结果,该结果中共打印了6条进程信息,由此可知程序已实现了我们的最初设定,案例2实现成功。
进程创建是Linux编程学习中重要的一项,理解进程创建的过程,才能避免在日后的学习工作中创建进程时可能发生的一些错误,读者应能理解进程的创建过程,并熟练运用fork()函数,根据程序需求创建进程。
思考2:
观察案例2的输出结果,会发现输出结果有以下问题:
(1)子进程的编号不是递增的;
(2)终端提示符后面仍有子进程信息打印,而命令提示符在最后一行的开头闪烁。
这是为什么?
3、 父子进程间共享
当进程调用fork()函数创建子进程后,子进程可以访问到与父进程完全相同的代码信息、数据信息和堆栈信息,因此我们认为fork()函数调用后,系统将父进程空间中的数据完全给了子进程,其实不然。早期的Unix系统确实采用完全复制的方式,但这种方式即浪费空间,又消耗时间,效率比较低下;现在的Unix和Linux系统经过优化,在调用fork()函数时,采用“读时共享,写时复制”机制。
在讲解读写机制前,我们先来了解fork()函数工作的详细过程:fork()函数创建子进程后,子进程获得了父进程的数据空间、堆栈、页表等的复制,此时父子进程中变量的虚拟地址相同,虚拟地址对应的物理地址也相同,父子进程共享物理内存中的页面信息,但为了防止一方修改,导致另一方出现访问异常,系统将页面信息标记为只读,fork()函数执行完毕。
之后父子进程都继续向下执行:此时子进程中拥有与父进程相同的页表,若进程只需进行数据的访问,到对应的物理地址中便能获取数据,因为父子进程相同的虚拟空间对应相同的物理地址,其访问机制如图4所示:
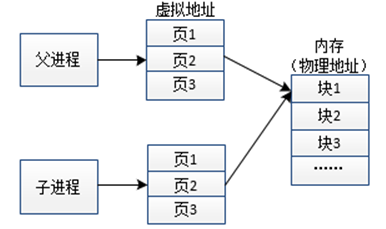
图4 读时共享
若子进程要对数据段、堆栈中的数据进行修改,系统将待操作的数据复制到内存中一块新的区域,修改副本数据权限为可写,之后子进程修改数据的副本,如此父子进程就能保存各自的数据,父子进程中相同的虚拟地址对应内存中不同的物理地址。访问机制如图5所示:系统将物理块1中待修改的数据赋值到物理块2,子进程访问物理块2中数据,执行修改操作。
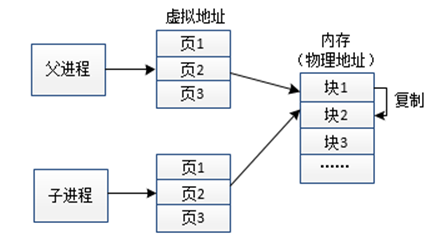
图5 写时复制
需要注意的是,同样的虚拟地址可能会对应不同的物理地址。这是因为虚拟地址是与进程关联的,每个进程都有一段0~4G的虚拟内存,因此多个进程中会有数据处于相同的虚拟地址;但“虚拟内存”只是系统管理内存的一种技术,目的是使进程认为自己拥有的是一段连续的地址空间,方便地址分配与数据管理,但它不是“实际”的,进程中的数据实际存在于内存对应的物理空间,因此同样的虚拟地址可以对应不同的物理地址。
 多学一招:进程的执行顺序
多学一招:进程的执行顺序
读者是否留意到前面小节中的思考1与思考2?出现这种情况,是因为父进程先于子进程终止。在Linux系统中,子进程应由父进程回收,但是当子进程被创建后,它与它的父进程及其它进程共同竞争系统资源,所以父子进程执行的顺序是不确定的,终止的先后顺序也是不确定的。
案例1中,父进程先于子进程终止,子进程变为“孤儿进程”,后由进程init接收;案例2中,创建了5个子进程,这5个子进程与父进程共同竞争资源,6个进程使用cpu的顺序不确定,因此子进程的编号不是递增关系,父进程在子进程尚未全部终止前便终止。另外,父进程是一个前台进程,当它终止退出后,会释放命令提示符,输出当前工作路径及终端提示符“[itheima@localhost ~]$|”,但此时尚有子进程仍在执行,终端仍有信息输出,因此命令提示符会出现在输出结果最后一行的开头。
解决这种问题的方法不止一种,读者容易理解的方法是:使用sleep()函数,暂缓进程执行。以案例2为例,在其中添加sleep()函数,修改后的代码如下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int main()
6 {
7 pid_t pid;
8 int i;
9 for(i=0;i<5;i++){
10 if((pid=fork())==0)
11 break;
12 }
13 if(pid==-1){
14 perror("fork error");
15 exit(1);
16 }
17 else if(pid>0){
18 sleep(5);
19 printf("parent pid=%d\n",getpid());
20 }
21 else if(pid==0){
22 sleep(i);
23 printf("I am child%d pid=%d\n",i+1,getpid());
24 }
25 return 0;
26 }重新编译该文件,执行程序,观察到每隔1秒,屏幕会打印一行信息,执行结果如下所示:
I am child1 pid=2906
I am child2 pid=2907
I am child3 pid=2908
I am child4 pid=2909
I am child5 pid=2910
parent pid=2905以上代码中让每个进程分别沉睡不同的时间,子进程在它之前创建的子进程执行之后执行,父进程等待所有子进程执行结束后执行。但这种方法只是权宜之计,因为内存中进程的实际运行状况是不确定的,实际情况中我们无法具预测程序所需的执行时间,若都使用sleep()函数控制进程的执行顺序,将会浪费cpu,降低cpu的运行效率。

隐藏目录