Spark HA集群部署
通过上一小节分析,Spark Standalone集群是主从架构的集群模式,因此同样存在单点故障问题,解决这个问题就需要用到Zookeeper服务,其基本原理是将Standalone集群连接到同一个Zookeeper实例并启动多个Master节点,利用Zookeeper提供的选举和状态保存功能,可以使一台Master节点被选举,另外一台Master节点处于Standby状态。当活跃的Master发生故障时,Standby状态的Master就会被激活,然后恢复集群调度,整个恢复过程可能需要1-2分钟。
Spark HA方案配置简单,首先启动一个Zookeeper集群,然后在不同节点上启动Master服务,需要注意的是,启动的节点必须与Zookeeper配置时保持相同,如果有读者未安装Zookeeper集群,请参考《Hadoop大数据技术与应用》完成Zookeeper集群环境的安装及配置,下面仅提供当前虚拟机中修改后的Zookeeper核心配置文件,如文件1所示。
文件1 zoo.cfg
1 tickTime=2000
2 initLimit=10
3 syncLimit=5
4 dataDir=/export/data/zookeeper/zkdata
5 clientPort=2181
6 server.1=hadoop01:2888:3888
7 server.2=hadoop02:2888:3888
8 server.3=hadoop03:2888:3888接下来,我们分步骤讲解配置Spark HA集群的操作方式。
1.修改spark-env.sh配置文件
在spark-env.sh文件中,将指定Master节点的配置参数注释,即在SPARK_MASTER_HOST配置参数前加“#”,表示注释当前行,添加SPARK_DAEMON_JAVA_OPTS配置参数,具体内容如下。
#指定Master的IP
\#export SPARK_MASTER_HOST=hadoop01
\#指定Master的端口
export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181
-Dspark.deploy.zookeeper.dir=/spark" 关于上述参数的具体说明如下所示:
- spark.deploy.recoveryMode:设置Zookeeper去启动备用Master模式。
- spark.deploy.zookeeper.url:指定ZooKeeper的Server地址。
- spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。
配置完成后,将spark-env.sh分发至hadoop02、hadoop03节点上,保证配置文件统一,命令如下。
$ scp spark-env.sh hadoop02:/export/servers/spark/conf
$ scp spark-env.sh hadoop03:/export/servers/spark/conf2.启动Spark HA集群
在普通模式下启动Spark集群,只需要通过/spark/sbin/start-all.sh一键启动脚本就可以了。然而,在高可用模式下启动Spark集群,首先需要启动Zookeeper集群,然后在任意一台主节点上执行start-all.sh命令启动Spark集群,最后在另外一台主节点上单独启动Master服务。具体步骤如下。
(1)启动Zookeeper服务
依次在三台节点上启动Zookeeper,命令如下。
$ zkServer.sh start (2)启动Spark集群
在hadoop01主节点使用一键启动脚本启动,命令如下。
$ /export/servers/spark/sbin/start-all.sh (3)单独启动Master节点
在hadoop02节点再次启动Master服务,命令如下。
$ /export/servers/spark/sbin/start-master.sh 启动成功后,通过浏览器访问http://hadoop02:8080,查看备用Master节点状态,如图1所示。
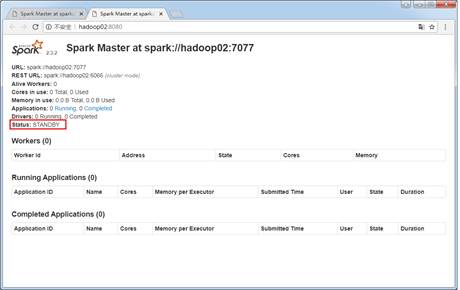
图1 启动Spark HA集群
通过图1可以看出,hadoop02节点的状态为STANDBY,说明Spark HA配置完毕。
3.测试Spark HA集群
Spark HA集群启动完毕后,为了演示是否解决了单点故障问题,可以关闭在hadoop01节点中的Master进程,用来模拟在生产环境中hadoop01突然宕机,命令如下所示。
$ /export/servers/spark/sbin/stop-master.sh 执行命令后,通过浏览器查看http://hadoop01:8080,发现已经无法通过hadoop01节点访问Spark集群管理界面。大约经过1-2分钟后,刷新http://hadoop02:8080页面,可以发现hadoop02节点中的Status值更改为ALIVE,Spark集群恢复正常,说明Spark HA配置有效解决了单点故障问题,具体如图2所示。
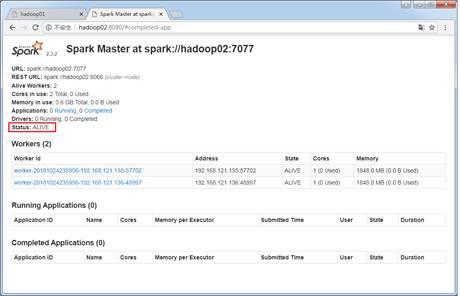
图2 验证Spark HA集群
&多学一招:脚本启动Zookeeper集群
在集群中启动Zookeeper服务时,需要依次在三台服务器上执行启动命令,然而在实际工作应用中,集群数量并非3台,当遇到数十台甚至更多的服务器时,就不得不编写脚本来启动服务了,编写脚本的语言有多种,这里采用Shell语言开发一键启动Zookeeper服务脚本,使用vi创建start_zk.sh文件,如文件2所示。
文件2 start_zk.sh
#! /bin/sh
for host in hadoop01 hadoop02 hadoop03
do
ssh $host "source /etc/profile;zkServer.sh start"
echo "$host zk is running"
done执行该文件只需要输入“sh start_zk.sh”即可启动集群中的Zookeeper服务。

隐藏目录