DStream输出操作
在Spark Streaming中,DStream的输出操作是真正触发DStream上所有转换操作进行计算(类似于RDD中的Action算子操作),然后经过输出操作,DStream中的数据才能与外部进行交互,比如将数据写入到分布式文件系统、数据库以及其他应用中。
下面,通过一张表来列举DStream API提供的与输出操作相关的方法,具体如表1所示。
表1DStream API提供的与输出操作相关的方法
| 方法名称 | 相关说明 |
|---|---|
| print() | 在Driver中打印出DStream中数据的前10个元素。 |
| saveAsTextFiles(prefix,[suffix]) | 将DStream中的内容以文本的形式进行保存,其中每次批处理间隔内产生的文件以“prefix-TIME_IN_MS[.suffix]”的方式命名。 |
| saveAsObjectFiles(prefix,[suffix]) | 将DStream中的内容按对象进行序列化,并且以SequenceFile的格式保存。每次批处理间隔内产生的文件以“prefix-TIME_IN_MS[.suffix]”的方式命名。 |
| saveAsHadoopFiles(prefix,[suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。 |
在表1中,列举了一些DStream API提供的与输出操作相关的方法。其中,prefix必须设置,表示文件夹名称的前缀;[suffix]是可选的,表示文件夹名后缀。
接下来,通过一个具体的案例来演示如何使用saveAsTextFiles()方法将nc(netcat命令的缩写,主要用于监听端口)交互界面输入的内容保存在HDFS的/user/root/saveAsTextFiles文件夹下,并将每个批次的数据单独保存为一个文件夹,其中prefix为文件夹前缀,suffix为文件夹的后缀,具体代码如文件1所示。
文件1 SaveAsTextFilesTest.scala
1 import org.apache.spark.{SparkConf, SparkContext}
2 import org.apache.spark.streaming.{Seconds, StreamingContext}
3 import org.apache.spark.streaming.dstream.ReceiverInputDStream
4 object SaveAsTextFilesTest {
5 def main(args: Array[String]): Unit = {
6 //1.设置本地测试环境
7 System.setProperty("HADOOP_USER_NAME", "root")
8 //2.创建SparkConf对象
9 val sparkConf: SparkConf = new SparkConf()
10 .setAppName("SaveAsTextFilesTest ").setMaster("local[2]")
11 //3.创建SparkContext对象,它是所有任务计算的源头
12 val sc: SparkContext = new SparkContext(sparkConf)
13 //4.设置日志级别
14 sc.setLogLevel("WARN")
15 //5.创建StreamingContext,需要两个参数,分别为SparkContext和批处理时间间隔
16 val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
17 //6.连接socket服务,需要socket服务地址、端口号及存储级别(默认的)
18 val dstream: ReceiverInputDStream[String] = ssc
19 .socketTextStream("192.168.121.134",9999)
20 //7.调用saveAsTextFiles操作,将nc交互界面输出的内容保存到HDFS上
21 dstream.saveAsTextFiles("hdfs://hadoop01:9000/data/root
22 /saveAsTextFiles/satf","txt")
23 ssc.start()
24 ssc.awaitTermination()
25 }
26 }上述代码中,第7行代码设置本地测试环境;第9-10行代码创建SparkConf对象,用于配置Spark环境;第12行代码创建SparkContext对象,用于操作Spark集群;第14行代码设置日志输出级别;第16-19行代码创建一个StreamingContext对象ssc,用于创建DStream对象,通过dstream对象连接Socket服务,获取实时的流数据;第21-22行代码调用saveAsTextFiles()方法,将nc交互界面输入的数据保存到HDFS上。
运行文件1中的代码,并通过访问浏览器查看HDFS的/data/root/saveAsTextFiles目录下的文件夹,效果如图1所示。
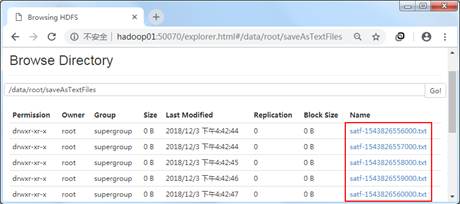
图1 查看HDFS的Web界面
从图1可以看出,HDFS的data/root/saveAsTextFiles目录下的文件夹均是以satf为前缀,txt为后缀,说明saveAsTextFiles()方法已经实现将nc交互界面的内容保存在HDFS上。

隐藏目录