集群模式执行Spark程序
集群模式是指将Spark程序提交至Spark集群中执行任务,由Spark集群负责资源的调度,程序会被框架分发到集群中的节点上并发地执行。下面分步骤介绍如何在集群模式下执行Spark程序。
1.添加打包插件
在实际工作应用中,代码编写完成后,需要将程序打包,上传至服务器运行,因此还需要向pom.xml文件中添加所需插件,具体配置参数如下。
1 <build>
2 <sourceDirectory>src/main/scala</sourceDirectory>
3 <testSourceDirectory>src/test/scala</testSourceDirectory>
4 <plugins>
5 <plugin>
6 <groupId>net.alchim31.maven</groupId>
7 <artifactId>scala-maven-plugin</artifactId>
8 <version>3.2.2</version>
9 <executions>
10 <execution>
11 <goals>
12 <goal>compile</goal>
13 <goal>testCompile</goal>
14 </goals>
15 <configuration>
16 <args>
17 <arg>-dependencyfile</arg>
18 <arg>${project.build.directory}/.scala_dependencies</arg>
19 </args>
20 </configuration>
21 </execution>
22 </executions>
23 </plugin>
24 <plugin>
25 <groupId>org.apache.maven.plugins</groupId>
26 <artifactId>maven-shade-plugin</artifactId>
27 <version>2.4.3</version>
28 <executions>
29 <execution>
30 <phase>package</phase>
31 <goals>
32 <goal>shade</goal>
33 </goals>
34 <configuration>
35 <filters>
36 <filter>
37 <artifact>*:*</artifact>
38 <excludes>
39 <exclude>META-INF/*.SF</exclude>
40 <exclude>META-INF/*.DSA</exclude>
41 <exclude>META-INF/*.RSA</exclude>
42 </excludes>
43 </filter>
44 </filters>
45 <transformers>
46 <transformer implementation=
47 "org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
48 <mainClass></mainClass>
49 </transformer>
50 </transformers>
51 </configuration>
52 </execution>
53 </executions>
54 </plugin>
55 </plugins>
56 </build>小提示:
如果在创建Maven工程中选择Scala原型模板,上述插件会自动创建。这些插件的主要功能是方便开发人员进行打包。
2.修改代码,打包程序
在打包项目之前,需要对词频统计的代码进行修改,创建WordCount_Online.scala文件,代码如文件1所示。
文件1 WordCount_Online.scala
1 import org.apache.spark.{SparkConf, SparkContext}
2 import org.apache.spark.rdd.RDD
3 //编写单词计数程序,打成Jar包,提交到集群中运行
4 object WordCount_Online {
5 def main(args: Array[String]): Unit = {
6 //1.创建SparkConf对象,设置appName
7 val sparkconf = new SparkConf().setAppName("WordCount_Online")
8 //2.创建SparkContext对象,它是所有任务计算的源头
9 //它会创建DAGScheduler和TaskScheduler
10 val sparkContext = new SparkContext(sparkconf)
11 //3.读取数据文件,RDD可以简单的理解为是一个集合,存放的元素是String类型
12 **val data : RDD[String] = sparkContext.textFile(args(0))**
13 //4.切分每一行,获取所有的单词
14 val words :RDD[String] = data.flatMap(_.split(" "))
15 //5.每个单词记为1,转换为(单词,1)
16 val wordAndOne :RDD[(String, Int)] = words.map(x =>(x,1))
17 //6.相同单词汇总,前一个下划线表示累加数据,后一个下划线表示新数据
18 val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
19 //7.把结果数据保存到HDFS上
20 **result.saveAsTextFile(args(1))**
21 //8.关闭sparkContext对象
22 sparkContext.stop()
23 }
24 }上述第12行代码textFile(args(0))表示通过外部传入的参数用来指定文件路径,第20行代码表示将计算结果保存至HDFS中。其余代码与本地模式执行Spark程序代码相同。通过使用Maven Projects工具,双击“package”选项,即可自动将项目打成Jar包,如图1所示。
图1 Mavne工具打包
最终生成的Jar文件会被创建在项目的target目录中,如图2所示。
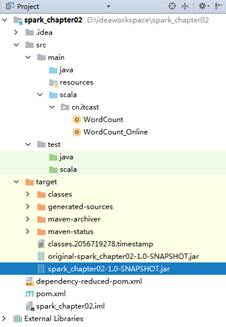
图2 打包地址
从图2可以看出,项目生成了两个Jar包,其中original包中不含有第三方Jar,将spark_chapter02-1.0-SNAPSHOT.jar包上传至hadoop01节点中的/export/data路径下。
2.执行提交命令
在hadoop01节点的spark目录下,执行“spark-submit”命令提交任务,命令如下。
bin/spark-submit --master spark://hadoop01:7077 \
--class cn.itcast.WordCount_Online \
--executor-memory 1g \
--total-executor-cores 1 \
/export/data/spark_chapter02-1.0-SNAPSHOT.jar \
/spark/test/words.txt \
/spark/test/out 上述命令中,首先通过“--master”参数指定了Master节点地址,“--class”参数指定运行主类的全路径名称,然后通过“--executor-memory”和“--total-executor-cores”参数指定执行器的资源分配,最后指定Jar包所在的绝对路径。其中“/spark/test/words.txt”是文件2-3中第12行代码的输入参数args(0),表示需要计算的数据源所在路径,“/spark/test/out”是文件2-3中第20行代码输入参数args(1),表示程序计算完成后,输出结果文件存储路径。执行成功后,进入HDFS WEB页面查看/spark/test/out文件夹,如图3所示。
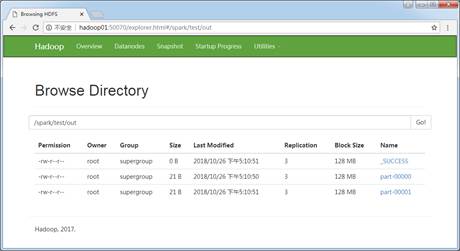
图3 输出结果文件
从图3可以看出,在/spark/test/out路径下生成了三个结果文件,其中_SUCCESS为标识文件,表示任务执行成功,part-文件为真正的输出结果文件。输出结果文件part-最终可以下载至本地或者使用Hadoop命令“-cat”查看,执行命令查看文件结果如下所示。
$ hadoop fs -cat /spark/test/out/part*
(itcast,1)
(hello,3)
(spark,1)
(hadoop,1)
隐藏目录