DStream转换操作
Spark Streaming中对DStream的转换操作会转变成对RDD的转换操作。为了更好的描述DStream是如何转换操作的,接下来,通过一张图来进行描述DStream的转换操作,具体如图1所示。
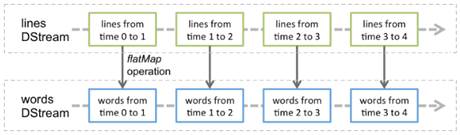
图1 DStream的转换操作
在图1中,lines表示转换操作前的DStream,words表示转换操作后生成的DStream。对lines做flatMap转换操作,也就是对它内部的所有RDD做flatMap转换操作。因此,在Spark Streaming中,可以通过RDD的转换算子生成新的DStream(即words)。
下面,通过一张表来列举DStream API提供的与转换操作相关的方法,具体如表1所示。
表1 DStream API提供的与转换操作相关的方法
| 方法名称 | 相关说明 |
|---|---|
| map(func) | 将源DStream的每个元素,传递到函数func中进行转换操作,得到一个新的DStream |
| flatMap(func) | 与map()相似,但是每个输入的元素都可以映射0或者多个输出结果 |
| filter(func) | 返回一个新的DStream,仅包含源DStream中经过func函数计算结果为true的元素 |
| repartition(numPartitions) | 用于指定DStream分区的数量 |
| union(otherStream) | 返回一个新的DStream,包含源DStream和其他DStream中的所有元素 |
| count() | 统计源DStream中每个RDD包含的元素个数,返回一个新的DStream |
| reduce(func) | 使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚合操作,返回一个新DStream |
| countByValue() | 计算DStream中每个RDD内的元素出现的频次,并返回一个新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次 |
| reduceByKey(func,[numTasks]) | 当一个类型为(K,V)键值对的DStream被调用时,则返回一个类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总得到的注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下为8),可以通过配置参数numTasks来设置不同的并行任务数 |
| join(otherStream,[numTasks]) | 当被调用类型分别为(K,V)和(K,W)键值对的两个DStream 时,返回类型为(K,(V,W))键值对的一个新DStream |
| cogroup(otherStream,[numTasks]) | 当被调用的两个DStream分别含有(K,V)和(K,W)键值对时,则返回一个(K,Seq[V],Seq[W])类型的新DStream |
| transform(func) | 通过对源DStream中的每个RDD应用RDD-to-RDD函数返回一个新DStream,这样就可以在DStream中做任意的RDD操作 |
| updateStateByKey(func) | 返回一个新状态的DStream,其中通过在键的先前状态和键的新值上应用给定函数func来更新每一个键的状态。该操作方法主要被用于维护每一个键的任意状态数据 |
在表1中,列举了一些DStream API提供的与转换操作相关的方法。DStream API提供的与转换操作相关的方法和RDD API有些不同,不同之处在于RDD API中没有提供transform()和update StateByKey()这两个方法。下面,主要对transform()和update StateByKey()这两个方法进行详细讲解。
- transform()
通过对源DStream中的每个RDD应用RDD-to-RDD函数返回一个新DStream,这样就可以在DStream中做任意的RDD操作。
接下来,通过一个具体的案例来演示如何使用transform()方法将一行语句分割成多个单词,具体实现步骤如下:
(1) 执行命令“nc –lk 9999”启动服务端且监听Socket服务(即Socket服务端口号为9999),并输入数据“I am learning Spark Streaming now”,具体命令如下:
[root@hadoop01 servers]# nc -lk 9999
I am learning Spark Streaming now(2) 打开IDEA开发工具,创建一个名称为“spark_chapter07”的Maven项目(跳过原型模板的选择)。
(3) 配置“pom.xml”文件,引入Spark Streaming相关依赖和设置源代码的存储路径。
引入Scala编程库、Spark核心库和Spark Streaming依赖主要用于编写Spark Streaming程序,具体内容如下:
<dependencies>
<!--引入Scala编程库依赖-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<!--引入spark核心依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.2</version>
</dependency>
<!--引入sparkStreaming依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
</build>配置好“pom.xml”文件后,需要在项目的/src/main和/src/test目录下分别创建scala目录,用来防止“sourceDirectory”和“testDirectory”标签提示错误。
(4) 在spark_chapter07项目的/src/main/scala目录下创建一个名为“cn.itcast.dstream”的包,接着在包下创建名为“TransformTest”的scala类,主要用于编写SparkStreaming应用程序,实现一行语句分割成多个单词的功能,具体代码如文件1所示。
文件1 TransformTest.scala
1 import org.apache.spark.streaming.dstream.{DStream,ReceiverInputDStream}
2 import org.apache.spark.streaming.{Seconds, StreamingContext}
3 import org.apache.spark.{SparkConf, SparkContext}
4 object TransformTest {
5 def main(args: Array[String]): Unit = {
6 //1.创建SparkConf对象
7 val sparkConf: SparkConf = new SparkConf()
8 .setAppName("TransformTest ").setMaster("local[2]")
9 //2.创建SparkContext对象,它是所有任务计算的源头
10 val sc: SparkContext = new SparkContext(sparkConf)
11 //3.设置日志级别
12 sc.setLogLevel("WARN")
13 //4.创建StreamingContext,需要两个参数,分别为SparkContext和批处理时间间隔
14 val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
15 //5.连接socket服务,需要socket服务地址、端口号及存储级别(默认的)
16 val dstream: ReceiverInputDStream[String] =
17 ssc.socketTextStream("192.168.121.134",9999)
18 //6.使用RDD-to-RDD函数,返回新的DStream对象(即words),并空格切分每行
19 val words: DStream[String] = dstream.transform(rdd => rdd
20 .flatMap(_.split(" ")))
21 //7.打印输出结果
22 words.print()
23 //8.开启流式计算
24 ssc.start()
25 //9.用于保持程序一直运行,除非人为干预停止
26 ssc.awaitTermination()
27 }
28 }上述代码中,第6-8行代码创建SparkConf对象,用于配置Spark环境;第10行代码创建一个SparkContext对象sc,用于操作Spark集群;第12行代码设置日志输出级别;第14-17行代码创建StreamingContext对象,用于创建DStream对象,通过dstream对象连接socket服务,获取实时的流数据;第19行代码通过dstream对象的transform()方法将实时的流数据用空格进行切分。
运行文件1中的代码,控制台输出如图2所示。
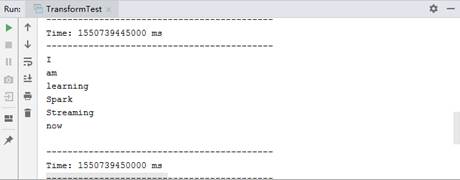
图2 transform()方法的操作
从图2可以看出,语句“I am learning Spark Streaming now” 在5s内被分割成6个单词。
- updateStateByKey()
返回一个新状态的DStream,其中通过在键的前一个状态和键的新值应用指定函数来更新每一个键的状态。
下面,通过一个具体的案例来演示如何使用updateStateByKey()方法进行词频统计。在spark_chapter07项目的/src/main/scala/cn.itcast.dstream目录下创建一个名为“UpdateStateByKeyTest”的scala类,主要用于编写Spark Streaming应用程序,实现词频统计,具体代码如文件2所示。
文件2 UpdateStateByKeyTest.scala
1 import org.apache.spark.streaming.dstream.{DStream,ReceiverInputDStream}
2 import org.apache.spark.streaming.{Seconds, StreamingContext}
3 import org.apache.spark.{SparkConf, SparkContext}
4 object UpdateStateByKeyTest {
5 //newValues 表示当前批次汇总成的(K,V)中相同K的所有V
6 //runningCount 表示历史的所有相同key的value总和
7 def updateFunction(newValues: Seq[Int], runningCount: Option[Int]):
8 Option[Int] = {
9 val newCount =runningCount.getOrElse(0)+newValues.sum
10 Some(newCount)
11 }
12 def main(args: Array[String]): Unit = {
13 //1.创建SparkConf对象
14 val sparkConf: SparkConf = new SparkConf()
15 .setAppName("UpdateStateByKeyTest ").setMaster("local[2]")
16 //2.创建SparkContext对象,它是所有任务计算的源头
17 val sc: SparkContext = new SparkContext(sparkConf)
18 //3.设置日志级别
19 sc.setLogLevel("WARN")
20 //4.创建StreamingContext,需要两个参数,分别为SparkContext和批处理时间间隔
21 val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
22 //5.配置检查点目录,使用updateStateByKey方法必须配置检查点目录
23 ssc.checkpoint("./")
24 //6. 连接socket服务,需要socket服务地址、端口号及存储级别(默认的)
25 val dstream: ReceiverInputDStream[String] = ssc
26 .socketTextStream("192.168.121.134",9999)
27 //7.按空格进行切分每一行,并将切分出来的单词出现的次数记录为1
28 val wordAndOne: DStream[(String, Int)] = dstream.flatMap(_.split(" "))
29 .map(word =>(word,1))
30 //8.调用updateStateByKey操作,统计单词在全局中出现的次数
31 var result: DStream[(String, Int)] = wordAndOne
32 .updateStateByKey(updateFunction)
33 //9.打印输出结果
34 result.print()
35 //10.开启流式计算
36 ssc.start()
37 //11.用于保持程序运行,除非被干预停止
38 ssc.awaitTermination()
39 }
40 }上述代码中,第7-11行代码定义一个方法updateFunction(),用于计算每个时间间隔的累计结果;第14-15行代码创建SparkConf对象,用于配置Spark环境;第17行代码创建SparkContext对象,用于操作Spark集群;第19行代码设置日志输出级别;第21行代码创建StreamingContext对象,用于创建DStream对象,通过dstream对象连接socket服务,获取实时的流数据;第23行代码配置检查点目录(使用updateStateByKey()方法必须的配置该目录);第28行代码通过dstream对象的flatMap()和map()方法将实时的流数据用空格进行切分,并将出现单词的次数记为1;第31行代码DStream对象wordAndOne通过updateStateByKey()方法统计单词出现的次数。
运行文件2中的代码,在hadoop01 9999端口不断输入的单词,具体内容如下:
[root@hadoop01 servers]# nc -lk 9999
hadoop spark itcast
spark itcast从上述内容可以看出,在Linux系统的命令行输入了两次数据,然后观察IDEA工具控制台输出,输出的内容如图3所示。
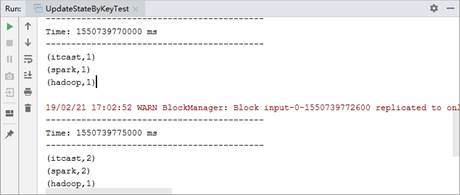
图3 updateStateByKey()方法的操作
从图3可以看出,IDEA工具的控制台每隔5s接收一次数据,一共接收到两次数据,并且每接收一次数据就会进行词频统计并输出结果。

隐藏目录