特殊字符处理
在XML文档中,有些字符具有特殊的意义,解析器在解析它时不会将其当做一般字符按照其原始意义进行处理,例如,在XML文档中,“<JavaWeb详解>”会被看作是一个元素,而不是一个书名。接下来,通过一个案例来演示这种情况,如例1所示。
例1 book.xml
1 <?xml version="1.0" encoding="gb2312"?>
2 <书架>
3 <书>
4 <书名><JavaWeb详解></书名>
5 <作者>张孝祥</作者>
6 <售价>58.00元</售价>
7 </书>
8 <书>
9 <书名>EJB3.0入门经典</书名>
10 <作者>黎活明</作者>
11 <售价>39.00元</售价>
12 </书>
13 </书架>用IE9.0以下的浏览器打开book.xml文件,结果如图1所示。
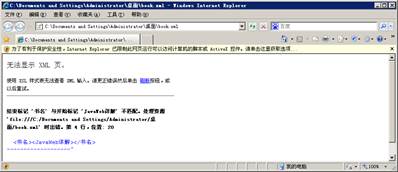
图1 运行结果
例1出现了错误,错误提示“结束标记‘书名’与开始标记‘JavaWeb详解’不匹配”。这是因为在XML文档被解析时,“<JavaWeb详解>”被看作是一个开始标记,而元素的开始标记必须和结束标记成对出现,所以,当浏览器找不到</JavaWeb详解>结束标记时,就会报告图1所示的错误。
为了解决图1所示的问题,XML针对这些特殊字符提供了对应的转义字符。在XML文档中,表示这些特殊字符的转义字符序列称为预定义实体。表1-1列举了XML文档中的特殊字符和预定义实体的对应关系,具体如下:
表1-1特殊字符和预定义实体的对照表
| 特殊字符 | 预定义实体 |
|---|---|
| & | & |
| < | < |
| > | > |
| “ | " |
| ‘ | ' |
表1中,列举了预定义实体在XML文档中的替代字符,接下来对例1进行修改,将“<JavaWeb详解>”中的“<”字符修改成“<”字符序列,“>”字符修改成“>”字符序列,注意“<”和“>”中的分号不能省略,修改后的book.xml文件如例2所示。
例2 book.xml
1 <?xml version="1.0" encoding="gb2312"?>
2 <书架>
3 <书>
4 <书名><JavaWeb详解></书名>
5 <作者>张孝祥</作者>
6 <售价>58.00元</售价>
7 </书>
8 <书>
9 <书名>EJB3.0入门经典</书名>
10 <作者>黎活明</作者>
11 <售价>39.00元</售价>
12 </书>
13 </书架>保存文档后,再次用浏览器打开,这时浏览器中显示了正确的“<”和“>”字符,如图2所示。
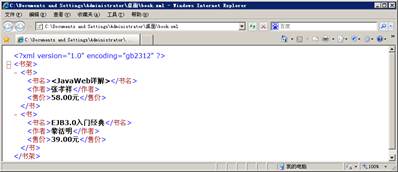
图2 运行结果

点击此处
隐藏目录
隐藏目录