Body Tag接口
在实现自定义标签时,有时需要对标签体的内容进行处理以后再向浏览器输出,比如将小写英文字母转化为大写,将HTML标签进行转义等等。为了实现这样的功能,JSP规范中定义了一个BodyTag接口,它继承自IterationTag接口,并在IterationTag接口基础上新增了两个方法和一个静态常量,具体如下:
1、EVAL_BODY_BUFFERED常量
如果标签处理器类实现了BodyTag接口,它的doStartTag()方法除了可以返回SKIP_BODY和EVAL_BODY_INCLUDE常量之外,还可以返回EVAL_BODY_BUFFERED常量。当doStartTag()方法返回EVAL_BODY_BUFFERED常量时,JSP容器将会创建一个javax.servlet.jsp.tagext.BodyContent对象,使用该对象来执行标签体。关于BodyContent类的用法,将在下面进行详细地讲解。
2、setBodyContent(BodyContent b)方法
当且仅当doStartTag()方法返回EVAL_BODY_BUFFERED常量时,JSP容器才会调用setBodyContent()方法,通过该方法将BodyContent对象传递给标签处理器类使用。
3、doInitBody()方法
JSP容器在调用setBodyContent()方法后会调用doInitBody()方法来完成一些初始化工作,该方法的调用在标签体执行之前。
其中,最重要的是setBodyContent()方法。为了帮助大家更好地理解BodyTag接口处理标签内容的方式,有必要对BodyContent类进行详细讲解。
BodyContent类是JspWriter类的子类,它在JspWriter的基础上增加了一个用于存储数据的缓冲区(确切地说缓冲区是在BodyContent的子类org.apache.jasper.runtime.BodyContentImple中定义的),当调用BodyContent对象的方法写数据时,数据将被写入到BodyContent内部的缓冲区中。
明白了BodyContent类的这个特点,就不难理解JSP容器是如何利用BodyContent对象来处理标签体内容了。当标签处理器类的doStartTag()方法返回EVAL_BODY_BUFFERED常量时,JSP容器会创建一个BodyContent对象,然后调用该对象的write()方法将标签体的内容写入BodyContent对象的缓冲区中,开发者只要能够访问BodyContent缓冲区的内容,就能对标签体的内容进行处理。在BodyContent类中定义了一些用于访问缓冲区内容的方法,具体如表1所示。
表1 BodyContent类的常用方法
| 方法声明 | 功能描述 |
|---|---|
| String getString() | 以字符串的形式返回BodyContent对象缓冲区中保存的数据 |
| Reader getReader() | 返回一个关联BodyContent对象缓冲区中数据的Reader对象,通过Reader对象可以读取缓冲区中的数据 |
| void clearBody() | 用于清空BodyContent对象缓冲区中的内容 |
| JspWriter getEnclosingWriter() | 用于返回BodyContent对象中关联的JspWriter对象。当JSP容器创建BodyContent对象后,PageContext对象中的“out”属性不再指向JSP的隐式对象,而是指向新创建的BodyContent对象。同时,在BodyContent对象中会用一个JspWriter类型的成员变量enclosingWriter记住原来的隐式对象,getEnclosingWriter()方法返回的就是原始的JSP隐式对象 |
| writerOut(Writer out) | 用于将BodyContent对象中的内容写入到指定的输出流 |
在表1列举的所有方法中,其中getEnclosingWriter()方法最难理解,但是,大家只需要记住该方法的返回值为out即可。
除了BodyContent类外,在BodyTag接口还会涉及到很多常量和方法,为了大家更好地掌握标签处理器的执行流程,接下来,通过一张图来描述,具体如图1所示。
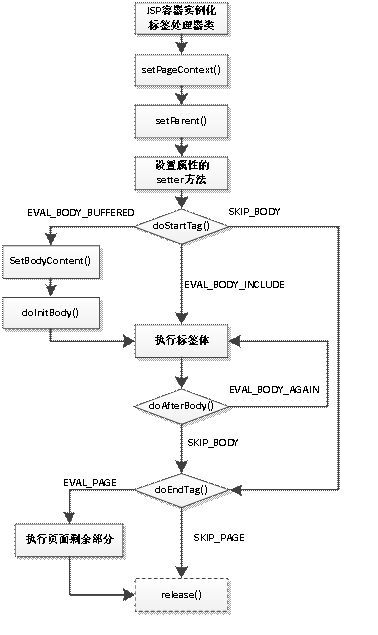
图1 标签处理器的执行流程
图2清楚地描述了JSP容器执行标签处理器的过程。其中release()方法之所以使用虚线是因为这个方法不会在标签处理器每次执行都被JSP容器调用,只有当标签处理器对象作为垃圾被回收之前它才会被调用。传统标签的处理器是单例的,只会被创建和销毁一次。
接下来,通过实现自定义标签<itcast: toUpperCase >,学习如何使用BodyTag接口将标签体中的小写英文字母转换为大写,具体步骤如下:
(1)编写标签处理器类ToUpperCase.java。
JSP规范中定义了一个类BodyTagSupport实现了BodyTag接口,为了简化程序的编写,标签处理器类ToUpperCase.java只需要继承BodyTagSupport类即可。ToUpperCase.java类的实现代码如例1所示。
例1 ToUpperCase.java
1 package cn.itcast.chapter09.classisctag;
2 import java.io.IOException;
3 import javax.servlet.jsp.JspException;
4 import javax.servlet.jsp.tagext.BodyTagSupport;
5 public class ToUpperCase extends BodyTagSupport {
6 //定义doEndTag()方法
7 public int doEndTag() throws JspException {
8 //获取缓冲区中数据
9 String content = getBodyContent().getString();
10 //将数据转为大写
11 content= content.toUpperCase();
12 try {
13 //输出数据内容(两种方式均可)
14 //pageContext.getOut().write(content);
15 bodyContent.getEnclosingWriter().write(content);
16 } catch (IOException e) {
17 e.printStackTrace();
18 }
19 return super.doEndTag();
20 }
21 }由于BodyTagSupport类中的doStartTag()方法默认返回EVAL_BODY_BUFFERED常量,JSP容器会会在执行标签体之前创建BodyContent对象,然后将标签体内容通过setBodyContent()方法设置给BodyContent对象。因此在例1中的doEndTag()方法中可以直接使用getBodyContent()方法的getString()方法获得写入到BodyContent缓冲区中的内容,然后将其转换为大写,通过调用getEnclosingWriter()方法获取到out对象,将内容输出到浏览器中。
注意:不能直接使用doStartTag()方法的原因是,执行doStartTag()方法时,BodyContent对象中还没有缓存标签体的内容,因此通过getBodyContent()方法还无法获得标签的内容。
(2)注册标签处理器类。
在mytag.tld文件中增加一个Tag元素,对标签处理器类进行注册,注册信息如下所示:
<tag>
<name>toUpperCase</name>
<tag-class>cn.itcast.chapter09.classisctag.ToUpperCase</tag-class>
<body-content>JSP</body-content>
</tag>(3)编写JSP页面toUpperCase.jsp。
在JSP页面中使用<itcast: toUpperCase >标签,在标签体中写入26个小写的英文字母,如例2所示。
例2 toUpperCase.jsp
1 <%@ page language="java" pageEncoding="GBK"%>
2 <%@taglib uri="http://www.itcast.cn" prefix="itcast"%>
3 <html>
4 <head>
5 <title>HelloWorld Tag</title>
6 </head>
7 <body>
8 <itcast:toUpperCase >
9 abcdefghijklmnopqrstuvwxyz
10 </itcast:toUpperCase >
11 </body>
12 </html>(4)启动Tomcat服务器,在浏览器地址栏输入URL地址http://localhost:8080/chapter09/toUpperCase.jsp访问toUpperCase.jsp页面,浏览器显示的结果如图2所示。
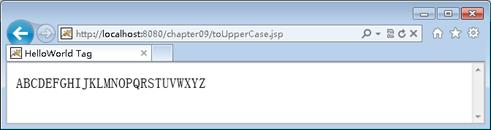
图2 运行结果
从运行结果可以看出,自定义标签<itcast: toUpperCase >,成功将标签体中的小写英文字母转换为大写。

隐藏目录