在MySQL数据库中存储链路数据
在前面小节中我们使用Spring Cloud Sleuth整合Zipkin实现了服务链路的追踪,但遗憾的是链路数据存储在内存中,无法做到持久化。Zipkin的持久化可以结合 Elasticsearch、Cassandra或MySQL实现。本节将在Spring Cloud Sleuth结合Zipkin已经实现服务链路追踪的基础上整合MySQL实现链路数据的持久化。
这里我们在9.2节案例的基础上改造zipkin-server项目来实现MySQL存储
链路数据。具体步骤如下:
(1)在zipkin-server的pom文件中加入Zipkin的MySQL存储依赖zipkin-storage-mysql、MySQL的连接器依赖mysql-connector-java、JDBC的起步依赖spring-boot-starter-jdbc以及dbcp连接池依赖commons-dbcp2等,具体代码如下所示。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId
<artifactId>zipkin-autoconfigure-storage-mysql</artifactId>
<version>2.11.5</version>
</dependency>
<dependency>
<groupId>io.zipkin.zipkin2</groupId>
<artifactId>zipkin-storage-mysql-v1</artifactId>
<version>2.11.5</version>
</dependency>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq</artifactId>
<version>3.11.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>注意:
由于Spring Boot 2.0之后官方不再建议自定义Zipkin,建议使用官方提供的zipkin.jar包,将Spring Boot升级至2.0后,发现Zipkin2使用MySQL做日志存储会出错,需要添加以下依赖:
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq</artifactId>
<version>3.11.4</version>
<dependency>另外启动的时候发现,Zipkin使用Spring Boot 2.0 默认的数据库连接池hikaricp会有问题,无法启动,这里改成了dbcp2数据库连接池,如下所示:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.3.0</version>
</dependency>(2)在zipkin-server项目的application.yml配置文件中加入数据源的配置,例如数据库的url、用户名、密码、连接驱动、初始化模式、dbcp连接池的一些属性、项目启动时需要初始化的建表语句的路径、Zipkin的存储方式等,具体代码如例1所示。
例1 zipkin-server\src\main\resources\application.yml
1 server:
2 port: 9411
3 spring:
4 application:
5 name: zipkin-server
6 datasource:
7 url:
8 jdbc:mysql://localhost:3306/zipkin?
9 autoReconnect=true&useUnicode=true&cha
10 racterEncoding=UTF-8&zeroDateTimeBehavior=
11 convertToNull&useSSL=false&serverTimezone=GMT%2B8
12 username: root
13 password: root
14 driver-class-name: com.mysql.jdbc.Driver
15 initialization-mode: always
16 continue-on-error: true
17 schema: classpath:/zipkin.sql
18 dbcp2:
19 initial-size: 50
20 max-wait-millis: 60000
21 max-idle: 100
22 default-auto-commit: true
23 default-read-only: false
24 test-on-borrow: true
25 type: org.apache.commons.dbcp2.BasicDataSource
26 rabbitmq:
27 host: localhost
28 port: 5672
29 username: guest
30 password: guest
31 eureka:
32 client:
33 service-url:
34 defaultZone: http://localhost:7000/eureka/
35 management:
36 metrics:
37 web:
38 server:
39 auto-time-requests: false #关闭自动收集web请求
40 zipkin:
41 storage:
42 type: mysql在例1中,第17行代码设置了项目启动时需要初始化的建表文件的路径,第18-25行代码设置了dbcp连接池的一些属性,包括初始化连接数、连接最大等待时间、是否只读、最大空闲连接数等,第40-42行代码设置了Zipkin存储方式为MySQL。
Zipkin持久化数据需要建立三张表用于存储数据,这三张表会在服务启动的时候自动在MySQL中创建。指定建表文件路径的配置如下所示。
spring:
datasource:
schema: classpath:/zipkin.sql(3)在application.yml文件同级目录下创建一个zipkin.sql文件,zipkin.sql文件的sql语句内容如下所示。
● 创建zipkin_spqns表的sql语句
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means
the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE
utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';● 创建zipkin_annotations表的sql语句
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';● 创建zipkin_dependencies表的sql语句
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);(4)启动测试。依次启动服务eureka-server、zipkin-server、eureka-provider、
eureka-consumer、gateway-service,在浏览器访问http://localhost:9410/eureka-provider/service1,访问效果如图1所示。
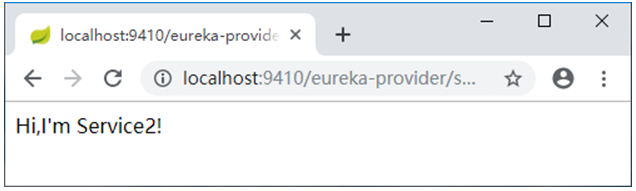
图1 访问效果图
此时,我们查看MySQL数据库,Zipkin已经自动在MySQL创建了三张表,表结构如图2所示。
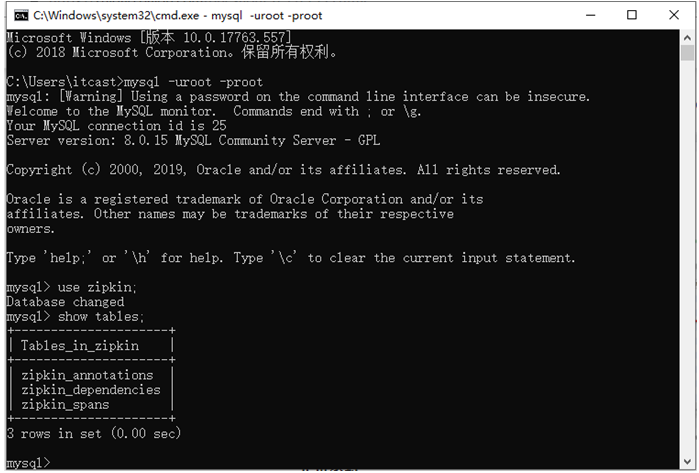
图2 Mysql中zipkin数据库的表结构图
链路追踪数据存储到了MySQL数据库中,如图3所示。
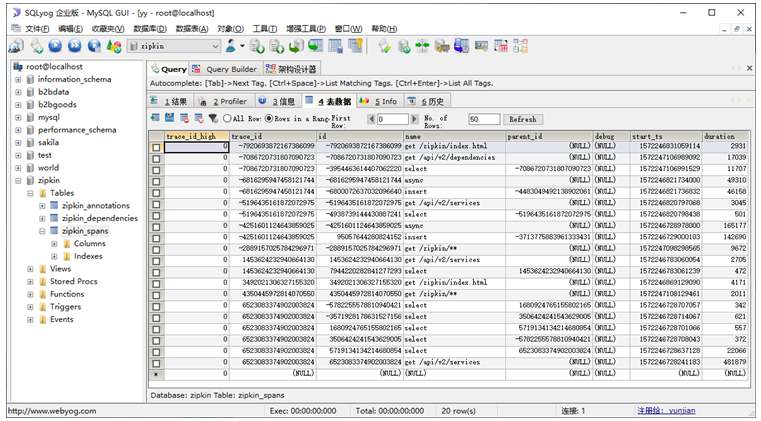
图3 链路追踪数据存储到MySQL数据库中的效果图
接下来,我们访问Zipkin的UI页面,可以发现,参与链路追踪的服务有MySQL和zipkin-server,访问效果如图2所示。
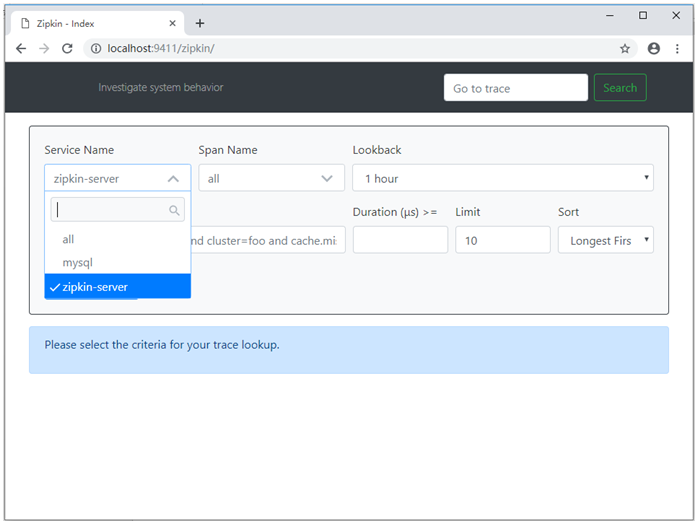
图2 Zipkin的UI界面效果图
选择zipkin-server,可以查看他的链路追踪的详细信息,如图3所示。
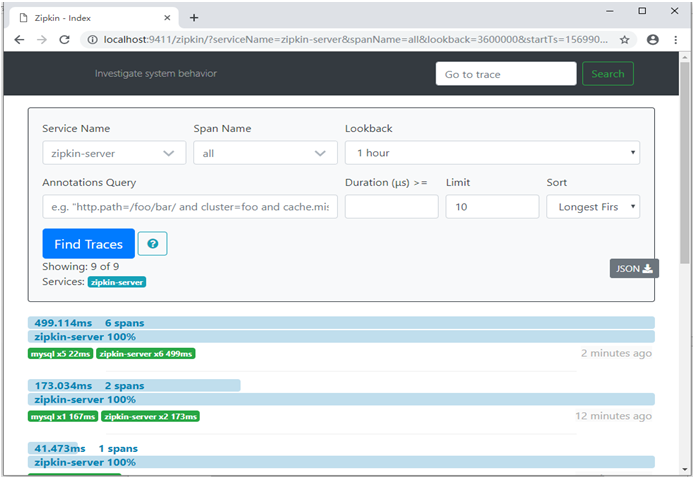
图3 链路追踪的详细信息图
在图3中,zipkin-server和MySQL之间存在链路关系,也就是说zipkin-server和MySQL进行了交互,说明zipkin-server将链路数据存储到了MySQL数据库中。
单击Dependencies可以查看服务之间的链路关系,如图4所示。
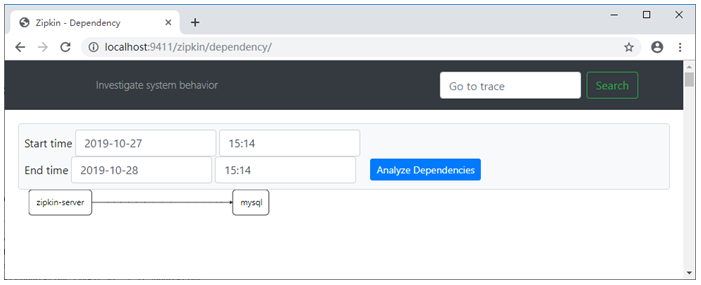
图4 服务链路追踪关系图
重启zipkin-server服务,依旧可以查询到链路数据,说明持久化成功。

隐藏目录