XPath开发工具
对于编写网络爬虫或做网页分析的人而言,会在定位和获取XPath路径上花费大量的时间,当爬虫框架成熟以后,又会花费大量的时间来解析网页。针对这些情况,Python提供了一些好用的插件或工具,主要包含如下几种:
XMLQuire:开源的XPath表达式编辑工具。
XPath Helper:适用于Chrome浏览器。
XPath Checker:使用于Firefox浏览器。
下面以XPath Helper为例,介绍一下如何使用XPath Helper插件,查找与XPath表达式相匹配的结果,具体步骤如下:
(1)在Chrome浏览器打开当当网网站,在左侧的商品分类中选择“图书、童书”,并点击右侧的“排行榜->图书畅销榜”,跳转到图书畅销榜的网页,如图1所示。
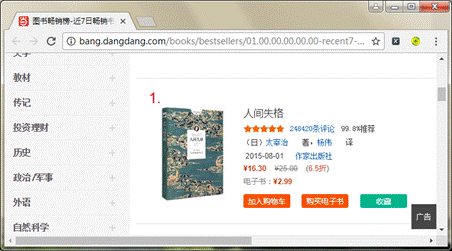
图1 当当网站的畅销榜
(2)上下滚动上述网页,可以看到当前页共推荐了20本图书。在图1中的链接文字“人间失格”上右击“检查”,该窗口的底部显示了网页源码的弹窗,并且定位到“人间失格”所对应的元素位置,其对应的源码具体如下:
<div class="name">
<a href="http://product.dangdang.com/23761145.html"target="_blank"
title="人间失格" class="">人间失格</a>
</div>(3)点击地址栏右侧的“ ”图标,打开XPath Helper工具,其对应界面如图2所示。
”图标,打开XPath Helper工具,其对应界面如图2所示。

图2 XPath Helper界面
在图2中,左侧的编辑区域用于输入路径表达式,右侧用于显示匹配到的结果,并且将总数显示到上面标签的括号中,如“RESULTS(20)”,默认为0。
(4)分析上述的源码信息,如果要获取所有书籍的名称,那么需要在编辑区域输入如下表达式:
//div[@class="name"]/a/@title(5)此时,右侧显示了所有匹配到的书籍标题,如图3所示。
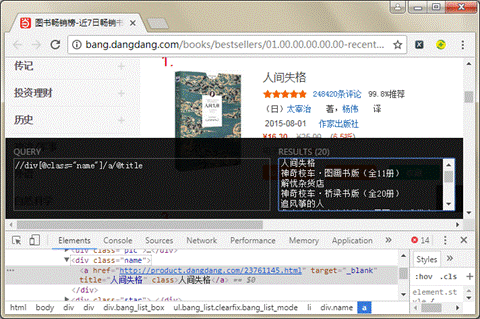
图3 使用XPath Helper获取到书籍标题
在测试表达式时,要查询的路径既可以从根节点开始,也可以从任何位置的节点开始,这个表示路径的语句并不是唯一的。

点击此处
隐藏目录
隐藏目录