明确抓取目标
第二步就是明确爬虫项目要抓取的内容。我们使用某培训公司的讲师介绍页面做为示例,该页面的网址如下: http://www.itcast.cn/channel/teacher.shtml,页面内容如图1所示。mySpider项目的抓取内容就是该页面中所有讲师的姓名、级别和个人信息等数据,这就明确了该项目的抓取目标。
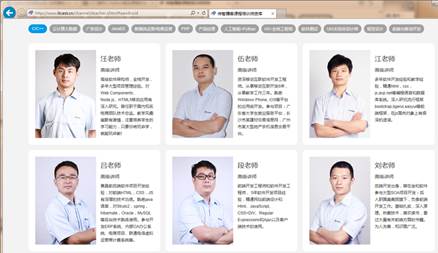
图1 讲师介绍页面
Scrapy使用Item(实体)来表示要爬取的数据。Item定义结构化数据字段,有点像Python中的字典dict,但是提供了一些额外的保护以减少错误。
Scrapy框架提供了基类scrapy.Item用来表示实体数据。我们一般需要创建一个继承自scrapy.Item的子类,并为该子类添加类型为scrapy.Field的类属性来表示爬虫项目的实体数据(可以理解成类似于ORM的映射关系)。
在PyCharm中打开mySpider目录下的items.py文件,可以看到Scrapy框架已经在items.py文件中自动生成了继承自scrapy.Item的MyspiderItem类。我们只需要修改MyspiderItem类的定义,为它添加属性即可。代码如下。
import scrapy
class MyspiderItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()在上述代码中,为MyspiderItem类添加了3个属性:name、title、和info,分别用于表示讲师的姓名、级别、和个人信息。

点击此处
隐藏目录
隐藏目录