Tesseract引擎的下载和安装
Tesseract是一个开源的OCR库,目前由Google赞助。截止到现在,Tesseract仍是公认最优秀、最精确的开源OCR系统,具有精准度高、灵活性高等特点,不仅可以通过训练识别出任何字体(只要字体的风格保持不变即可),而且可以识别出任何Unicode字符。
Tesseract支持60种以上的语言,它提供了一个引擎和命令行工具。要想在Windows系统下使用Tesseract,需要先安装Tesseract-OCR引擎,可以从网址https://github.com/UB-Mannheim/tesseract/wiki进行下载,如图1所示。
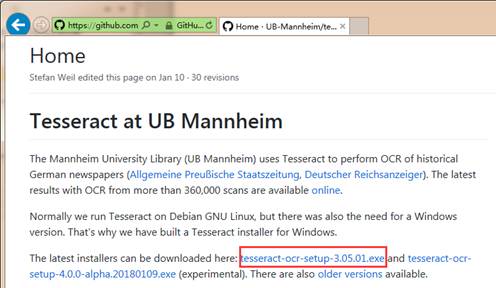
图1 开始安装Tesseract-OCR
该网址提供的下载版本为3.05.01,下载完成后,双击安装文件,按照默认设置进行安装。默认情况下,安装文件会为其配置系统环境变量,以指向安装目录。这样,可以在任意目录下使用tesseract命令运行。如果没有配置环境变量,可以手动进行设置,默认安装目录为:
C:\Program Files (x86)\Tesseract-OCR打开命令行窗口,输入tesseract命令进行验证。如果安装成功,则会输出如图2所示的信息。
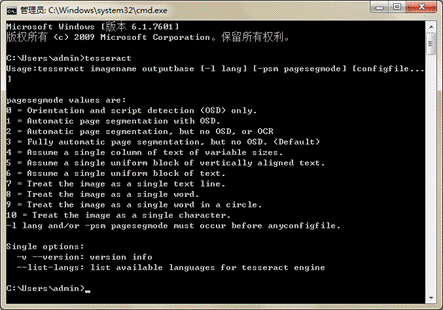
图2 安装Tesseract-OCR成功
在Tesseract的安装目录下,默认有个 tessdata目录,该目录中存放的是语言字库文件,如图3所示。其中,chi_sim.traineddata存放的是中文字库,其余的都是英文字库。
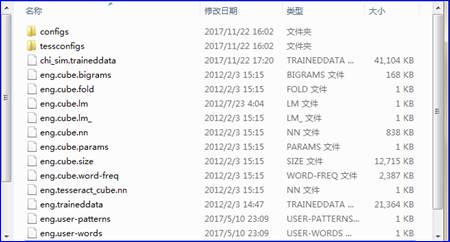
图3 tessdata目录下的字库文件

点击此处
隐藏目录
隐藏目录