什么是Beautiful Soup
截止到目前,BeautifulSoup(3.2.1版本)已经停止开发,官网推荐现在的项目使用beautifulsoup4(BeautifulSoup 4版本,简称为bs4)开发。
bs4是一个HTML/XML的解析器,主要的功能是解析和提取HTML/XML数据。它不仅支持CSS选择器,而且支持Python标准库中的HTML解析器,以及lxml的XML解析器,通过使用这些转化器,实现了惯用的文档导航和查找方式,节省了大量的工作时间,提高了开发项目的效率。
bs4库会将复杂的HTML文档换成树结构(HTML DOM),这个结构中的每个节点都是一个Python对象,这些对象可以归纳为如下四种:
bs4.element.Tag类:表示HTML中的标签,最基本的信息组织单元。它有两个非常重要的属性,分别为表示标签名字的name属性,表示标签属性的attrs属性。
bs4.element.NavigableString类:表示HTML中标签的文本(非属性字符串)。
bs4.BeautifulSoup类:表示HTML DOM中的全部内容,支持遍历文档树和搜索文档树的大部分方法。
bs4.element.Comment类:表示标签内字符串的注释部分,是一种特殊的NavigableString对象。
使用bs4的一般流程如下:
第1步:创建一个BeautifulSoup类型的对象
根据HTML或者文件创建BeautifulSoup对象。
第2步:通过上述对象的操作方法进行解读搜索
根据DOM树进行各种节点的搜索(比如,find_all方法可以搜索出所有满足要求的节点,find方法只会搜索出第一个满足要求的节点),只要获得了一个节点,就可以访问节点的名称、属性和文本。
第3步:利用DOM树结构标签的特性,进行更为详细的节点信息提取
在搜索节点的时候,我们也可以按照节点的名称、节点的属性或者节点的文字进行搜索。
上述流程如图1所示。
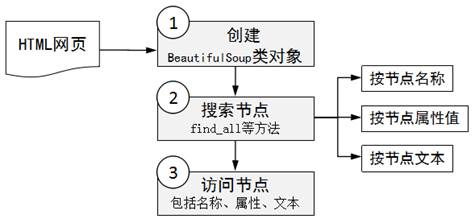
图1 bs4库的使用流程

隐藏目录