多线程爬虫流程分析
由于外部网络不稳定,在使用单线程爬取网页数据时,如果有一个网页响应速度慢或者卡住了,那整个程序都要等待下去,这显然是无效率的。因此,我们可以使用多线程、多进程、协程技术来实现并发下载网页。
那么,在Python中多线程、多进程和协程应该如何选择呢?
一般来说,多进程适用于CPU密集型的代码,例如各种循环处理、大量的密集并行计算等。多线程适用于I/O密集型的代码,例如文件处理、网络交互等。协程无需通过操作系统调度,没有进程、线程之间的切换和创建等开销,适用于大量不需要CPU的操作,例如网络I/O等。
实际上,限制爬虫程序发展的瓶颈就在于网络I/O,原因是网络I/O的速度赶不上CPU的处理速度。结合多线程、多进程和协程的特点和用途,我们一般采用多线程和协程技术来实现爬虫程序。
线程爬虫将多线程技术运用在采集网页信息和解析网页内容上,它的流程如图1所示。
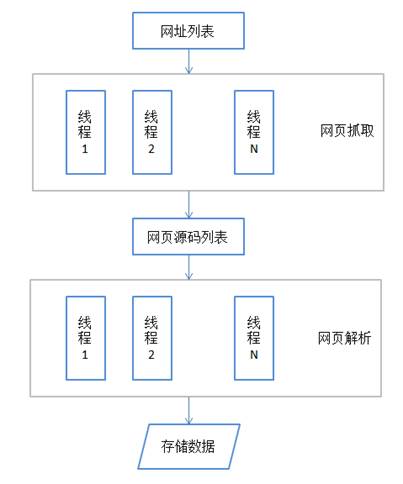
图1 多线程爬虫流程
(1)首先有一个网址列表,是要爬取数据的网页列表。与单线程爬虫不同,多线程爬虫可以同时爬取多个网页,所以需要准备一个待爬取网址列表。
(2)同时启动多个线程抓取网页内容。一般启动固定数量的线程,一个线程抓取完一个网页之后,接着抓取下一个。线程的数量不宜过多,否则,线程调度的时间太长,效率低;线程的数量也不宜过少,否则不能最大限度地提高爬取速度。
(3)将抓取到的网页源码存储在一个列表里。
(4)同时使用多个线程对网页源码表里的网页内容进行解析。
(5)将解析之后的数据存储起来。至此,就完成了多线程爬虫的全部过程。

点击此处
隐藏目录
隐藏目录