Scrapy-Redis的完整架构
图1是在Scrapy框架的基础上增加了Scrapy-Redis的架构图。
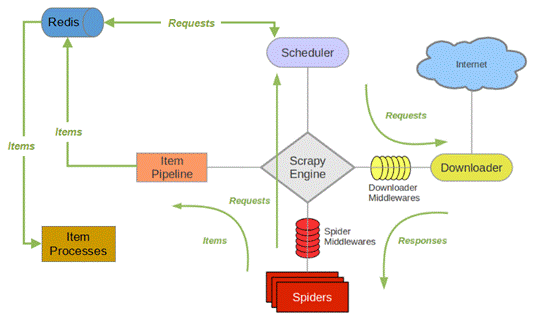
图1 Scrapy-Redis架构图
与之前的Scrapy架构图相比,图1所示的架构图在此基础上增加了Redis和Item Processes,关于这两个组件的介绍如下:
(1) Redis(REmote DIctionary Server):一个开源的、使用ANSI C语言编写的、支持网络交互的、可基于内存亦可持久化的Key-Value数据库,提供了多种语言的API。注意,这个数据库只用做存储URL,不关心爬取的具体数据,不要和前面介绍的MongoDB和MySQL产生混淆。
(2) Item Processes:Item集群。
通过观察图1可知,利用上述这套机制,将用作爬虫请求的调度问题、去重问题,以及Items的存储,都交给Redis进行处理,这样不仅能保持之前的记录,而且允许爬虫产生中断。
因为每个主机上的爬虫进程都访问同一个Redis数据库,所以调度和判重都统一进行管理,达到了分布式爬虫的目的。

点击此处
隐藏目录
隐藏目录