HashMap集合
HashMap集合是Map接口的一个实现类,它用于存储键值映射关系,该集合的键和值允许为空,但键不能重复,且集合中的元素是无序的。HashMap底层是由哈希表结构组成的,其实就是“数组+链表”的组合体,数组是HashMap的主体结构,链表则主要是为了解决哈希值冲突而存在的分支结构。正因为这样特殊的存储结构,HashMap集合对于元素的增、删、改、查操作表现出的效率都比较高。接下来,通过一张图来展示HashMap集合底层实现,如图1所示。
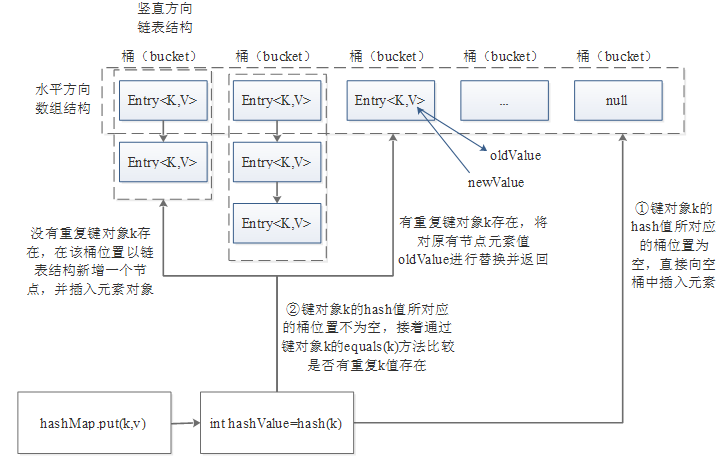
图1 HashMap集合内部结构及存储原理图
在图1所示结构中,水平方向以数组结构为主体并在竖直方向以链表结构进行结合的就是HashMap中的哈希表结构。在哈希表结构中,水平方向数组的长度称为HashMap集合的容量(capacity),竖直方向每个元素位置对应的链表结构称为一个桶(bucket),每个桶的位置在集合中都有对应的桶值,用于快速定位集合元素添加、查找时的位置。
图1中,在展示HashMap集合内部哈希表结构的基础上,也展示了存储元素的原理。当向HashMap集合添加元素时,首先会调用键对象k的hash(k)方法,快速定位并寻址到该元素在集合中要存储的位置。在定位到存储元素键对象k的哈希值所对应桶位置后,会出现两种情况:第一种情况,键对象k的hash值所在桶位置为空,则可以直接向该桶位置插入元素对象;第二种情况,键对象k的hash值所在桶位置不为空,则还需要继续通过键对象k的equals(k)方法比较新插入的元素键对象k和已存在的元素键对象k是否相同,如果键对象k相同,就会对原有元素的值对象v进行替换并返回原来的旧值,否则会在该桶的链表结构头部新增一个节点来插入新的元素对象。
接下来就通过一个案例来学习HashMap的基本用法,如文件1所示。
文件1 Example14.java
1 import java.util.HashMap;
2 import java.util.Map;
3 public class Example14 {
4 public static void main(String[] args) {
5 // 创建HashMap对象
6 Map map = new HashMap();
7 // 1、向Map存储键值对元素
8 map.put("1", "Jack");
9 map.put("2", "Rose");
10 map.put("3", "Lucy");
11 map.put("4", "Lucy");
12 map.put("1", "Tom");
13 System.out.println(map);
14 // 2、查看键对象是否存在
15 System.out.println(map.containsKey("1"));
16 // 3、获取指定键对象映射的值
17 System.out.println(map.get("1"));
18 // 4、获取集合中的键对象和值对象集合
19 System.out.println(map.keySet());
20 System.out.println(map.values());
21 // 5、替换指定键对象映射的值
22 map.replace("1", "Tom2");
23 System.out.println(map);
24 // 6、删除指定键对象映射的键值对元素
25 map.remove("1");
26 System.out.println(map);
27 }
28 }运行结果如图2所示。
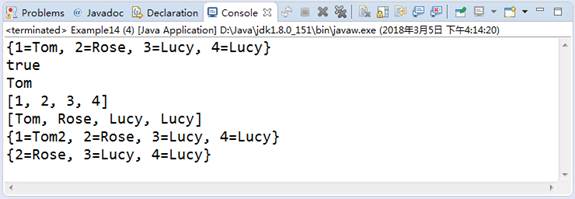
图2 运行结果
文件1中,首先使用Map的put(Object key,Object value)方法向集合中加入5个元素,然后通过HashMap的相关方法对集合中元素进行查询、修改、删除操作。从图2的结果可以看出,Map集合中的键具有唯一性,当向集合中添加已存在的键值元素时,会覆盖之前已存在的键值元素,如果需要可以接收返回来的旧值。
小提示:
在使用HashMap集合时,还需要考虑一个问题,如果通过键对象k定位到的桶位置不含链表结构,那么对于查找、添加等操作很快,仅需一次定位寻址即可;如果定位到的桶位置包含链表结构,对于添加操作,其时间复杂度依然不大,因为最新的元素会插入链表头部,只需要简单改变引用链即可;而对于查找操作来讲,此时就需要遍历链表,然后通过键对象k的equals(k)方法逐一查找比对,所以,从性能方面考虑,HashMap中的链表出现越少,性能才会越好,这就要求HashMap集合中的桶越多越好。
我们知道,HashMap的桶数目,就是集合中主体数组结构的长度,由于数组是内存中连续的存储单元,它占用的空间代价是很大的,但是它的随机存取速度是Java集合中最快的。通过增大桶的数量,而减少Entry<k,v>链表的长度,来提高从HashMap中读取数据的速度,这是典型的拿空间换时间的策略。但是我们不能刚开始就给HashMap分配过多的桶,这是因为数组是连续的内存空间,它的创建代价很大,况且我们也不能确定给HashMap分配多大的空间才够合理,为了解决这一个问题,HashMap内部采用了根据实际情况,动态地分配桶数量的策略。
HashMap这种动态分配桶的数量,是通过new HashMap()方法创建HashMap时,会默认集合容量capacity大小为16,加载因子loadFactor为0.75(HashMap桶多少权衡策略的经验值),此时该集合桶的阀值就为12(容量capacity与加载因子loadFactor的乘积),如果向HashMap集合中不断添加完全不同的键值对<k,v>,当超过12个存储元素时,HashMap集合就会默认新增加一倍桶的数量(也就是集合的容量),此时集合容量就变为32。当然,如果开发者对存取效率要求的不是太高,想节省点空间的话,可以使用new HashMap(int initialCapacity, float loadFactor)构造方法,在创建HashMap集合时指定集合容量和加载因子,并将这个加载因子设置得大一些。

隐藏目录