Hadoop集群初体验
前面完成了Hadoop集群安装和测试,显示构建的Hadoop集群能够正常运行。接下来,就通过Hadoop经典案例——单词统计,来演示Hadoop集群的简单使用。
(1)打开HDFS的UI界面,选择【Utilities】→【Browse the file system】查看分布式文件系统里的数据文件,可以看到新建的HDFS系统上没有任何数据文件,如图1所示。
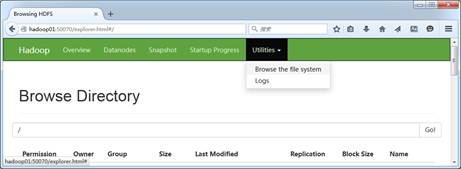
图1 HDFS文件系统
(2)先在集群主节点hadoop01上的/export/data/目录下,使用“vi word.txt”指令新建一个word.txt文本文件,并编写一些单词内容,如文件所示。
文件 word.txt
hello itcast
hello itheima
hello hadoop
接着,在HDFS文件系统上创建/wordcount/input目录,并将word.txt文件上传至该目录下,具体指令如下所示。
$ hadoop fs -mkdir -p /wordcount/input
$ hadoop fs -put /export/data/word.txt /wordcount/input 上述指令是Hadoop提供的进行文件系统操作的HDFS Shell相关指令,此处不必深究具体使用,在下一章节会进行详细说明。执行完上述指令后,再次查看HDFS的UI界面,会发现/wordcount/input目录创建成功并上传了指定的word.txt文件,如图2所示。
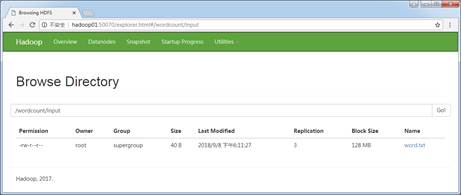
图2 HDFS文件系统
(3)进入Hadoop解压包中的share/hadoop/mapreduce/目录下,使用ll指令查看文件夹内容,如图3所示。
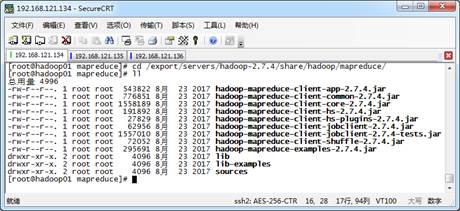
图3 官方MapReduce示例程序
从图3可以看出,在该文件夹下自带了很多Hadoop的MapReduce示例程序。其中,hadoop-mapreduce-examples-2.7.4.jar包中包含了计算单词个数、计算Pi值等功能。
因此,这里可以直接使用hadoop-mapreduce-examples-2.7.4.jar示例包,对HDFS文件系统上的word.txt文件进行单词统计,来进行此次案例的演示,在当jar包位置执行如下指令。
$ hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output上述指令中,hadoop jar hadoop-mapreduce-examples-2.7.4.jar表示执行一个Hadoop的jar包程序;wordcount表示执行jar包程序中的单词统计功能;/wordcount/input表示进行单词统计的HDFS文件路径;/wordcount/output表示进行单词统计后的输出HDFS结果路径。
执行完上述指令后,示例包中的MapReduce程序开始运行,此时可以通过YARN集群的UI界面查看运行状态,如图4所示。
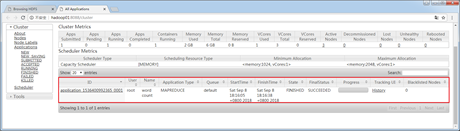
图4 YARN集群UI界面
经过一定时间执行后,再次刷新查看YARN集群的UI界面,就会发现程序已经运行成功的状态信息以及其他相关参数。
(4)在单词统计的示例程序执行成功后,再次刷新并查看HDFS的UI界面,如图5所示。
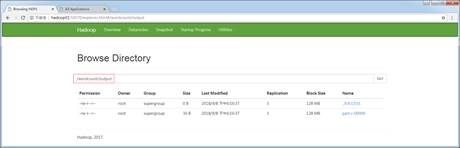
图5 MapReduce程序执行结果
从图5可以看出,MapReduce程序执行成功后,在HDFS上自动创建了指定的结果目录/wordcount/output,并且输出了_SUCCESS和part-r-00000结果文件。其中_SUCCESS文件用于表示此次任务成功执行的标识,而part-r-00000表示单词统计的结果。
接着,就可以单击下载图2-48中的part-r-00000结果文件到本地操作系统,并使用文本工具(EditPlus、Nodepad++、记事本等)打开该文件,如图6所示。
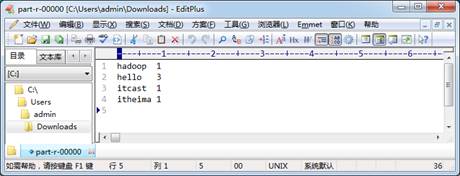
图6 MapReduce单词统计结果文件
从图6可以看出,MapReduce示例程序成功统计出了/wordcount/input/word.txt文本中的单词数量,并进行了结果输出。
在本节使用Hadoop提供的示例程序演示了单词统计案例的实现,在实际工作应用开发中,开发者需要根据需求自行编写各种MapReduce程序,打包上传至服务器上,然后执行此程序。关于Hadoop系统的工作原理,以及MapReduce程序编写方式,将在后面的章节进行详细讲解。
注意:
在执行MapReduce程序时,可能会出现类似 “WARN hdfs.DFSClient:Caught exception”的警告提示信息,这是由于Hadoop版本以及系统资源配置的原因,读者可以不必在意,它并不会影响程序的正常执行。

隐藏目录