Hive桶表操作
为了将表进行更细粒度的范围划分,我们可以创建桶表。桶表,是根据某个属性字段把数据分成几个桶(我们这里设置为4,默认值是-1,可自定义),也就是在文件的层面上把数据分开。下面通过一个案例进行桶表相关操作的演示。
首先,我们先开启分桶功能,命令如下所示。
hive> set hive.enforce.bucketing = true;
//由于HQL最终会转成MR程序,所以分桶数与ReduceTask数保持一致,
//从而产生相应的文件个数
hive> set mapreduce.job.reduces=4;其次,创建桶表,语法格式如下所示:
hive> create table stu_buck(Sno int,Sname string,
Sex string,Sage int,Sdept string)
clustered by(Sno) into 4 buckets
row format delimited fields terminated by ',';执行上述语句后,桶表stu_buck创建完成,并且以学生编号(Sno)分为4个桶,以“,”为分隔符的桶表。
再次,在HDFS的/stu/目录下已有结构化数据文件student.txt,我们需要将student.txt文件的复制到/hivedata目录下。然后,加载数据到桶表中,由于分桶表加载数据时,不能使用Load Data方式导入数据(原因在于该Load Data本质上是对数据文件进行复制或移动到Hive表所对应的地址中),因此在分桶表导入数据时需要创建临时的student表,该表与stu_buck表的字段必须一致,语法格式如下所示:
hive> create table student_tmp(Sno int,Sname string,
Sex string,Sage int,Sdept string)
row format delimited
fields terminated by ',';依次,加载数据至student表,语法格式如下所示:
hive> load data local inpath '/hivedata/student.txt'
into table student_tmp;最后,将数据导入stu_buck表,语法格式如下所示:
hive> insert overwrite table stu_buck
select * from student_tmp cluster by(Sno);按照步骤,执行上述语句,然后查看桶表stu_buck中的数据,效果如图1所示。
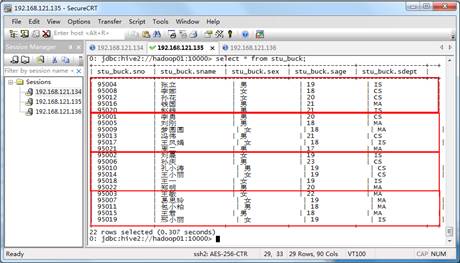
图1 stu_buck的数据
从图1中可以看出,数据已经按照学生编号(Sno)分为4桶。我们可以通过查看HDFS的WEB UI页面,效果如图2所示。
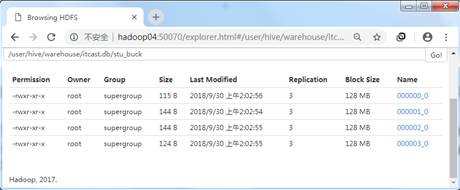
图2 分桶文件结构
在图2中,数据文件已经被分为四个文件,针对每桶的数据可以使用Hadoop命令去查看数据内容,具体命令如下所示:
$ hadoop fs –cat /user/hive/warehouse/itcast.db/stu_buck/000000_0执行上述命令,效果如图3所示。
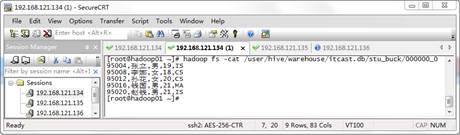
图3 000000文件中的数据
在图3中,学生编号以分桶原理(分桶字段取Hash值与桶个数取模),将数据归并到一个文件中。
总体来说,分桶表是把表所映射的结构化数据分得更细致,且分桶规则与MapReduce分区规则一致,Hive采用对目标列值进行哈希运算,得到哈希值再与桶个数取模的方式决定数据的归并,从而看出Hive与MapReduce存在紧密联系。使用分桶可以提高查询效率,例如执行Join操作时,两个表有相同的列字段,如果对这两张表都采取了分桶操作,那么就可以减少Join操作时的数据量,从而提高查询效率。它还能够在处理大规模数据集时,选择小部分数据集进行抽样运算,从而减少资源浪费。

隐藏目录