MapTask工作原理
MapTask作为MapReduce工作流程的前半部分,它主要经历了5个阶段,分别是Read阶段、Map阶段、Collect阶段、Spill阶段和Combiner阶段,如图1所示。
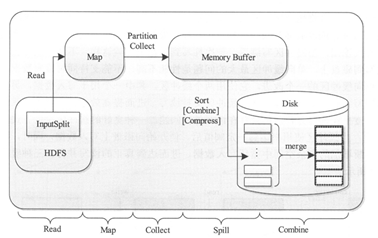
图1 MapTask工作原理
关于MapTask这5个阶段的相关介绍如下:
(1)Read 阶段:MapTask通过用户编写的RecordReader,从输入的InputSplit中解析出一个个key/value。
(2)Map 阶段:将解析出的key/value交给用户编写的map()函数处理,并产生一系列新的key/value 。
(3)Collect阶段:在用户编写的map()函数中,数据处理完成后,一般会调用outputCollector.collect()输出结果,在该函数内部,它会将生成的key/value分片(通过调用partitioner),并写入一个环形内存缓冲区中。
(4)Split阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
(5)Combine阶段:当所有数据处理完成以后,MapTask会对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。

点击此处
隐藏目录
隐藏目录