HDFS的演变
HDFS 源于 Google 在2003年10月份发表的GFS(Google File System)论文,接下来,我们从传统的文件系统入手,开始学习分布式文件系统,以及分布式文件系统是如何演变而来。
传统的文件系统对海量数据的处理方式是将数据文件直接存储在一台服务器上,如图1所示。
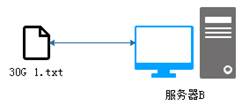
图1 传统文件系统
从图1可以看出,传统的文件系统在存储数据时,会遇到两个问题,具体如下:
l 当数据量越来越大时,会遇到存储瓶颈,就需要扩容;
l 由于文件过大,上传和下载都非常耗时;
为了解决传统文件系统遇到的存储瓶颈问题,那么首先考虑的就是扩容,扩容有两种形式,一种是纵向扩容,即增加磁盘和内存;另一种是横向扩容,即增加服务器数量。通过扩大规模从而达到分布式存储,这种存储形式就是分布式文件存储的雏形,如图2所示。

图2 分布式文件系统雏形
解决了分布式文件系统的存储瓶颈问题之后,那么还需要解决文件上传与下载的效率问题,常规的解决办法是将一个大的文件切分成多个数据块,将数据块以并行的方式进行存储。这里以30G的文本文件为例,将其切分成3块,每块大小10G(实际上每个数据块都很小只有100M左右),将其存储在文件系统中,如图3所示。

图3 分布式文件系统雏形
从图3可以看出,原先一台服务器要存储30G的文件,此时每台服务器只需要存储10G的数据块就完成了工作,从而解决了上传下载的效率问题。但是文件通过数据块分别存储在服务器集群中,那么如何获取一个完整的文件呢?针对这个问题,就需要再考虑增加一台服务器,专门用来记录文件被切割后的数据块信息以及数据块的存储位置信息,如图4所示。
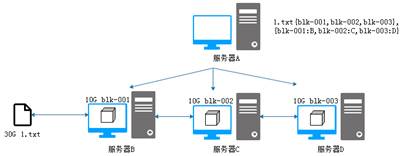
图4 HDFS文件系统雏形
从图4可以看出,文件存储系统中增加了一台服务器A用于管理其他服务器,服务器A记录着文件被切分成多少个数据块,这些数据块分别存储在哪台服务器中,这样当客户端访问服务器A请求下载数据文件时,就能够通过类似查找目录的方式查找数据了。
通过前面的操作,看似解决了所有问题,但其实还有一个非常关键的问题需要处理,那就是当存储数据块的服务器中突然有一台机器宕机,我们就无法正常的获取文件了,这个问题被称为单点故障。针对这个问题,可以采用备份的机制进行解决,如图5所示。
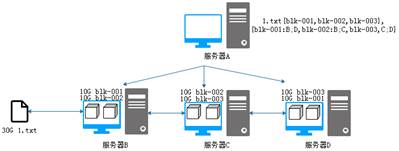
图5 HDFS文件系统
从图5可以看出,每个服务器中都存储两个数据块,进行备份。服务器B存储blk-001和blk-002,服务器C存储blk-002和blk-003,服务器D存储blk-001和blk-003。此时,当服务器C突然宕机,我们也可以通过服务器B和服务器D查询完整的数据块供客户端访问下载。此时就形成了简单的HDFS分布式文件系统。
这里的服务器A被称为NameNode,它维护着文件系统内所有文件和目录的相关信息,服务器B、C、D被称为DataNode,用于存储数据块。

隐藏目录