Hive分区表操作
分区表是按照属性在文件夹层面给文件更好的管理,实际上就是对应一个HDFS文件系统上的独立文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询指定的分区,这样的查询效率会提高很多。Hive分区表一共有两种,分别为普通分区和动态分区,我们下面就要对其分别进行介绍。
1、Hive普通分区
创建分区表分为两种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式,现在我们只针对单分区进行详解,若想学习多分区可以参考官网的官方文档。
现有结构化数据文件user_p.txt,文件中的数据内容如文件所示。
文件 user_p.txt
1,allen
2,tom
3,jerry首先,创建分区表。语法格式如下所示:
hive> create table t_user_p(id int, name string)
partitioned by (country string)
row format delimited fields terminated by ',';其次,加载数据是将数据文件移动到与Hive表对应的位置,从本地(Linux)复制或移动到HDFS文件系统的操作。由于分区表在映射数据时不能使用Hadoop命令移动文件,需要使用Load命令,其语法格式如下所示:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
INTO TABLE table_name [PARTITION (partcol1=val1, partcol2=val2 ...)]Load Data是HQL固定的数据装载语句,下面针对部分关键字进行讲解。
- Filepath:它可以引用一个文件(在这种情况下,Hive将文件移动到表所对应的目录中),或者它可以是一个目录(在这种情况下,Hive将把该目录中的所有文件移动到表所对应的目录中)。它可以是相对路径、绝对路径以及完整的URI。
- Local:如果指定了Local键字,Load命令将在本地文件系统(Hive服务启动方)中查找文件路径,将其复制到对应的HDFS路径下;如果没有指定Local关键字,它将会从HDFS中移动数据文件至对应的表路径下。
- Overwrite:如果使用了Overwrite关键字,当加载数据时目标表或分区中的内容会被删除,然后再将filepath指向的文件或目录中的内容添加到表或分区中。简单的说就是覆盖表中已有数据;若不添加该关键字,则表示追加数据内容。
加载数据操作的语法格式如下所示:
hive> load data local inpath '/hivedata/user_p.txt' into table t_user_p partition(country='USA');从上述语句看出,Load Data表示装载数据,Inpath表示数据文件所在的HDFS路径,partition(country=‘USA’)为指定的分区,它需要与建表时设置的分区字段保持一致。执行完上述命令后,查看表内容的数据,效果如图1所示:
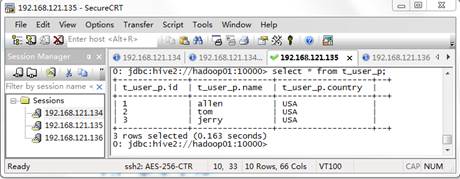
图1 t_user_p中的数据
从图1中可以看出,分区表与结构化数据完成映射。通过查看HDFS的WEB UI界面,我们可以看到Hive创建了以分区字段为名的文件夹,而该文件夹内存储的是结构化数据文件。效果如图2所示。
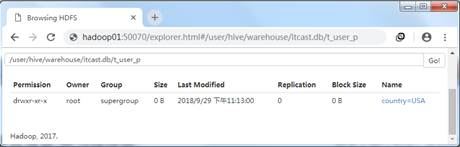
图2 分区文件
依次,新增分区。语法格式如下所示。
hive> ALTER TABLE table_name ADD PARTITION (country='China') location
'/user/hive/warehouse/itcast.db/t_user_p/country=China';上述语句中,ALTER TABLE是固定的HQL语句,用于新增数据表和修改数据表。执行上述语句,通过HDFS的WEB UI界面中可以看到新增的分区country=China。效果如图3所示。
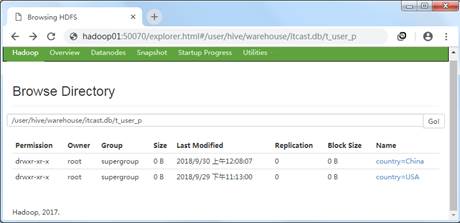
图3 新增分区
接着,修改分区。语法格式如下所示。
hive> ALTER TABLE table_name PARTITION (country='China') RENAME TO PARTITION (country='Japan');执行上述语句,通过HDFS的WEB UI界面中可以看到修改后的分区country=Japan。效果如图4所示。
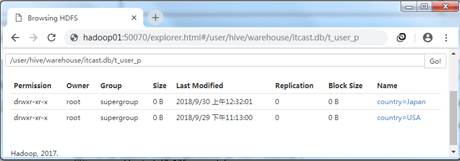
图4 修改分区
最后,删除分区。语法格式如下所示:
hive> ALTER TABLE table_name DROP IF EXISTS PARTITION (country='Japan');执行上述语句,通过HDFS的WEB UI界面已经看不到分区country=Japan。效果如图5所示。
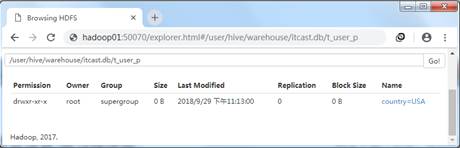
图5 删除分区
小提示:
分区字段不能与已存在字段重复,且分区字段是一个虚拟的字段,它不存放任何数据,该数据来源于装载分区表时所指定的数据文件。
2、Hive动态分区
上面介绍了Hive普通分区的创建和Load命令加载数据的操作。在默认情况下,我们加载数据时,需要手动的设置分区字段,并且针对一个分区就要写一个插入语句。如果源数据量很大时(例如,现有许多日志文件,要求按照日期作为分区字段,在插入数据的时候无法手动的添加分区),就可以利用Hive提供的动态分区,可以简化插入数据时的繁琐操作,若想实现动态分区,则需要开启动态分区功能,具体命令如下所示:
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;Hive默认是不支持动态分区的,因此hive.exec.dynamic.partition默认值为false,需要启动动态分区功能,可以将该参数设置为true;其中hive.exec.dynamic.partition.mode的默认值是strict,表示必须指定至少一个分区为静态分区,将此参数修改为nonstrict,表示允许所有的分区字段都可以使用动态分区。
在Hive中insert语句是用于动态插入数据的,不同的是它主要是结合select查询语句使用,且非常适用于动态分区插入数据,语法格式如下所示:
hive> insert overwrite table table_name
partition (partcol1[=val1], partcol2[=val2] ...)
select_statement FROM from_statement现有原始表的结构化数据文件dynamic_partition_table.txt,内容数据如文件所示。
文件 dynamic_partition_table.txt
2018-05-10,ip1
2018-05-10,ip2
2018-06-14,ip3
2018-06-14,ip4
2018-06-15,ip1
2018-06-15,ip2现在我们通过一个案例进行演示动态分区的数据插入操作。将dynamic_partition_table中的数据按照时间(day),插入到目标表d_p_t的相应分区中。
首先,创建原始表。语法格式如下所示:
hive> create table dynamic_partition_table(day string,ip string)
row format delimited fields terminated by ",";其次,加载数据文件至原始表,语法格式如下所示:
hive> load data local inpath
'/export/data/hivedata/dynamic_partition_table.txt'
into table dynamic_partition_table;再次,创建目标表,语法格式如下所示:
hive> create table d_p_t(ip string)
partitioned by (month string,day string);依次,动态插入,语法格式如下所示:
hive> insert overwrite table d_p_t partition (month,day)
select ip,substr(day,1,7) as month,day
from dynamic_partition_table;最后,查看目标表中的分区数据,语法格式如下所示:
hive> show partitions d_p_t;按照上述步骤,执行相应的语句后,最终的效果如图6所示:
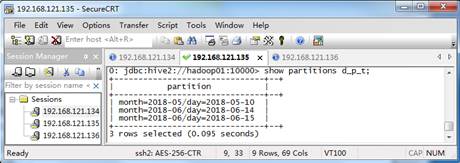
图6 目标表的分区数据
小提示:
动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都创建副分区静态列所定义的分区。

隐藏目录