MapReduce编程实例—词频统计
通过前面的介绍,相信大家对MapReduce的编程思想和模型有了概念上的了解,下面我们借助MapReduce编程的一个典型案例——词频统计, 来学习实现MapReduce编程开发。
假设我们有两个文本文件,这两个文本文件位于HDFS中,文件如1,2所示:
文件1 text1.txt
Hello World
Hello Hadoop
Hello itcast文件2 text2.txt
Hadoop MapReduce
MapReduce Spark根据MapReduce编程模型,那么单词计数的实现过程,如图1所示。
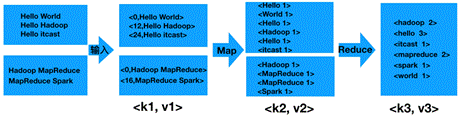
图1 词频统计过程
在图1演示中,首先,MapReduce通过默认组件TextInputFormat将待处理的数据文件(如text1.txt和text2.txt),把每一行的数据都转变为<key,value>键值对(其中,对应key为偏移量,value为这一行的文本内容);其次,调用Map()方法,将单词进行切割并进行计数,输出键值对作为Reduce阶段的输入键值对;最后,调用Reduce()方法将单词汇总、排序后,通过TextOutputFormat组件输出到结果文件中。

点击此处
隐藏目录
隐藏目录