MapReduce运行模式
MapReduce程序的运行模式主要有两种:
(1)本地运行模式:在当前的开发环境模拟MapReduce执行环境,处理的数据及输出结果在本地操作系统。
(2)集群运行模式:把MapReduce程序打成一个Jar包,提交至Yarn集群上去运行任务。由于Yarn集群负责资源管理和任务调度,程序会被框架分发到集群中的节点上并发的执行,因此处理的数据和输出结果都在HDFS文件系统中。
集群运行模式只需要将MapReduce程序打成Jar包上传至集群即可,比较简单,这里不再赘述。下面我们以词频统计为例,讲解如何将MapReduce程序设置为在本地运行模式。
在MapReduce程序中,除了要实现Mapper(代码见WordCountMapper.java文件)和Reduce(代码见WordCountReducer.java文件)外,我们还需要一个Driver类提交程序,具体代码,如文件所示。
文件 WordCountDriver.java
1 import org.apache.hadoop.conf.Configuration;
2 import org.apache.hadoop.fs.Path;
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.Text;
5 import org.apache.hadoop.mapreduce.Job;
6 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
7 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
8 public class WordCountDriver {
9 public static void main(String[] args) throws Exception {
10 //通过Job来封装本次MR的相关信息
11 Configuration conf = new Configuration();
12 // 配置MR运行模式,使用local表示本地模式,可以省略
13 **conf.set("mapreduce.framework.name", "local")**;
14 Job wcjob = Job.getInstance(conf);
15 // 指定MR Job jar包运行主类
16 wcjob.setJarByClass(WordCountDriver.class);
17 //指定本次MR所有的Mapper Reducer类
18 wcjob.setMapperClass(WordCountMapper.class);
19 wcjob.setReducerClass(WordCountReducer.class);
20 // 设置我们的业务逻辑 Mapper类的输出 key和 value的数据类型
21 wcjob.setMapOutputKeyClass(Text.class);
22 wcjob.setMapOutputValueClass(IntWritable.class);
23 // 设置我们的业务逻辑 Reducer类的输出 key和 value的数据类型
24 wcjob.setOutputKeyClass(Text.class);
25 wcjob.setOutputValueClass(IntWritable.class);
26 // 使用本地模式指定要处理的数据所在的位置
27 **FileInputFormat.setInputPaths(wcjob,"D:/mr/input")**;
28 // 使用本地模式指定处理完成之后的结果所保存的位置
29 **FileOutputFormat.setOutputPath(wcjob,new Path("D:/mr/output"))**;
30 // 提交程序并且监控打印程序执行情况
31 boolean res = wcjob.waitForCompletion(true);
32 System.exit(res ? 0 : 1);
33 **}**
34 **}在文件中,往Configuration对象中添加“mapreduce.framework.name=local”参数,表示程序为本地运行模式,实际上在hadoop-mapreduce-client-core-2.7.4.jar包下面的mapred-default.xml配置文件中,默认指定使用本地运行模式,因此mapreduce.framework.name=local配置也可以省略;同时,还需要指定本地操作系统源文件目录路径和结果输出的路径。当程序执行完毕后,就可以在本地系统的指定输出文件目录查看执行结果了。输出的结果,如图1所示。
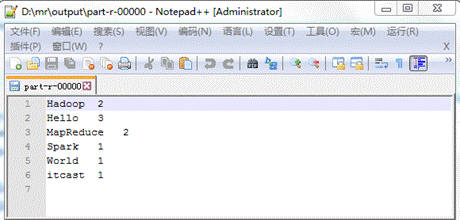
图1 词频案例的输出结果
小提示:
在使用本地运行模式执行wordcount案例时,即使配置了windows平台的hadoop,运行时仍报如下错误:
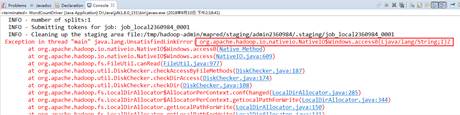
解决办法:根据错误提示和网上资料的提示,需要修改org.apache.hadoop.io.nativeio包下的NativeIO类的access()方法,将返回值直接设为true,即:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
// return access0(path, desiredAccess.accessRight());
**return true;**
}
隐藏目录