MySQL表数据子集导入
前面几个小节针对MySQL表数据的全表导入与增量导入进行了讲解,而在实际业务中,有时候开发人员可能需要只针对部分数据进行导入操作。针对上述需求,可以使用Sqoop提供的“--where”和“--query”参数,先进行数据过滤,然后再将满足条件的数据进行导入。
1.“--where”参数进行数据过滤
Sqoop提供的“--where”参数主要针对简单的数据过滤,例如,将表emp_add中“city=sec-bad”的数据导入HDFS中,具体指令示例如下。
$ sqoop import \
--connect jdbc:mysql://hadoop01:3306/userdb \
--username root \
--password 123456 \
**--where "city ='sec-bad'" \**
--target-dir /wherequery \
--table emp_add \
--num-mappers 1上述指令中,在MySQL表数据导入HDFS操作的基础上,添加了“--where "city ='sec-bad'"”(注意标点符号)参数对“city=sec-bad”的数据进行过滤,然后再导入到HDFS上。执行完指令后,使用“hadoop fs -cat /wherequery/part-m-00000”指令在指定的HDFS的/wherequery路径下查看结果文件,如图1所示。
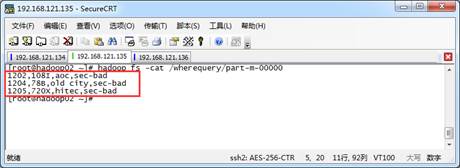
图1 导入HDFS目录内容
从图1可以看出,Sqoop成功将满足"city ='sec-bad'"条件的数据导入HDFS中。
2.“--query”参数进行数据过滤
Sqoop提供的“--query”参数主要针对复杂的数据过滤,参数后面可以添加SQL语句,更方便高效的进行导入数据。例如,将表emp中“id>1203”的数据的id、name和deg字段导入HDFS中,具体指令示例如下。
$ sqoop import \
--connect jdbc:mysql://hadoop01:3306/userdb \
--username root \
--password 123456 \
--target-dir /wherequery2 \
**--query 'SELECT id,name,deg FROM emp WHERE id>1203 AND $CONDITIONS'** \
--num-mappers 1上述代码示例中,使用了Sqoop的“--query”参数进行数据过滤,它的主要作用就是先通过该参数指定的查询语句查询出子集数据,然后再将子集数据进行导入。上述示例中, $CONDITIONS相当于一个动态占位符,动态的接收传过滤后的子集数据,然后让每个Map任务执行查询的结果并进行数据导入。
在使用Sqoop的“--query”参数进行数据导入时,要特别注意以下事项。
(1)如果没有指定“--num-mappers 1”(或-m 1,即map任务个数为1),那么在指令中必须还要添加“--split-by”参数。“--split-by”参数的作用就是针对多副本map任务并行执行查询结果并进行数据导入,该参数的值要指定为表中唯一的字段(例如主键id);
(2)“--query”参数后的查询语句中(例如示例中单引号中的SELECT语句),如果已经使用了WHERE关键字,那么在连接$CONDITIONS占位符前必须使用AND关键字;否则,就必须使用WHERE关键字连接;
(3)“--query”参数后的查询语句中的$CONDITIONS占位符不可省略,并且如果查询语句使用双引号(")进行包装,那么就必须使用$CONDITIONS,这样可以避免Shell将其视为Shell变量。
接着,就执行上述示例中的导入指令。执行完指令后,可以使用“hadoop fs -cat /wherequery2/part-m-00000”指令在指定的HDFS的/wherequery2路径下查看结果文件,如图2所示。
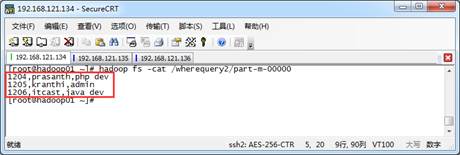
图2 导入HDFS目录内容
从图2可以看出,Sqoop成功将满足SELECT查询条件的数据的指定字段信息导入HDFS中。

隐藏目录