MapReduce核心思想
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。
为了更好地理解“分而治之”思想,我们先来举一个生活的例子。例如,某大型公司在全国设立了分公司,假设现在要统计公司今年的营收情况制作年报,有两种统计方式,第1种方式是全国分公司将自己的账单数据发送至总部,由总部统一计算公司今年的营收报表;第2种方式是采用分而治之的思想,也就是说,先要求分公司各自统计营收情况,再将统计结果发给总部进行统一汇总计算。这两种方式相比,显然第2种方式的策略更好,工作效率更高效。
MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段,具体介绍如下:
- Map阶段:负责将任务分解,即把复杂的任务分解成若干个“简单的任务”来并行处理,但前提是这些任务没有必然的依赖关系,可以单独执行任务。
- Reduce阶段:负责将任务合并,即把Map阶段的结果进行全局汇总。
下面通过一个图来描述上述MapReduce的核心思想,具体如图1所示。
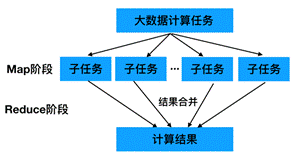
图1 MapReduce核心思想
从图1可知,MapReduce就是“任务的分解与结果的汇总”。即使用户不懂分布式计算框架的内部运行机制,但是只要能用Map和Reduce思想描述清楚要处理的问题,就能轻松地在Hadoop集群上实现分布式计算功能。

点击此处
隐藏目录
隐藏目录