读取HTML表格数据
在浏览网页时,有些数据会在HTML网页中以表格的形式进行展示,对于这部分数据,我们可以使用Pandas中的read_html()函数进行读取,并返回一个包含多个DataFrame对象的列表。read_html()函数的语法格式如下:
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None,skiprows=None,
attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ',
encoding=None, decimal='.', converters=None,na_values=None,
keep_default_na=True, displayed_only=True)上述函数中常用参数表示的含义如下:
(1) io:表示路径对象。
(2) header:表示指定列标题所在的行。
(3) index_col:表示指定行标题对应的列。
(4) attrs:默认为None,用于表示表格的属性值。
假设现在有一个HTML网页表格,该表格包含的数据如图1所示。
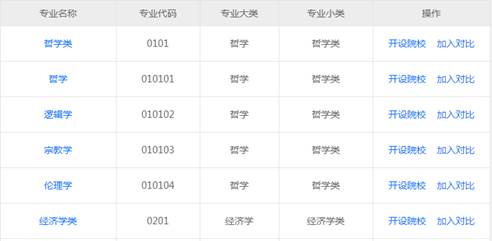
图1 网页表格数据
接下来,我们通过一个示例来演示如何使用read_html()函数读取HTML表格中的数据,具体代码如下:
In [85]: import pandas as pd
import requests
html_data = requests.get('http://kaoshi.edu.sina.com.cn/college/majorlist/')
html_table_data = pd.read_html(html_data.content,encoding='utf-8')
html_table_data[1]
Out[85]:
0 1 2 3 4
0 专业名称 专业代码 专业大类 专业小类 操作
1 哲学类 0101 哲学 哲学类 开设院校 加入对比
2 哲学 010101 哲学 哲学类 开设院校 加入对比
3 逻辑学 010102 哲学 哲学类 开设院校 加入对比
……………………………………部分数据省略…………………………
18 金融工程 020302 经济学 金融学类 开设院校 加入对比
19 保险学 020303 经济学 金融学类 开设院校 加入对比值得一提的是,在使用read_html()函数读取网页中的表格数据时,需要注意网页的编码格式。

点击此处
隐藏目录
隐藏目录