根据行索引合并数据
join()方法能够通过索引或指定列来连接DataFrame,其语法格式如下:
join(other,on = None,how ='left',lsuffix ='',rsuffix ='',sort = False)上述方法常用参数表示的含义如下:
(1) on:名称,元组或列表的名称,用于连接列名。
(2) how:可以从{''left'' ,''right'', ''outer'', ''inner''}中任选一个,默认使用左连接的方式。
(3) lsuffix:接收字符串,在左侧重叠的列名后添加后缀名。
(4) rsuffix:接收字符串,在右侧重叠的列名后添加后缀名。
(5) sort:接收布尔值,根据连接键对合并的数据进行排序,默认为False。
当两张表中如果没有重叠的索引可以设置merge()函数的left_index和right_index参数,而对join()方法来说只需要将表明做为参数传入即可。
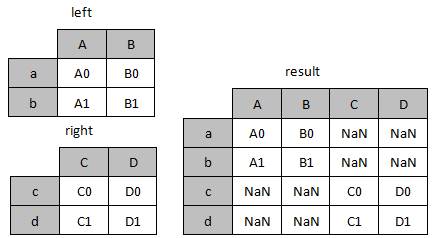
图1 合并示意图
join()方法默认使用的左连接方式,即以左表为基准,合并后左表的数据会全部展示,如图1所示left表与right表中没有重叠的索引。当使用左连接合并时,right表中的数据将不会展示出来,为了将right表中的数据展示出来我们可以将连接方式设置为外连接方式,具体如下:
In [30]: import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']})
right = pd.DataFrame({'C': ['C0', 'C1', 'C2'],'D': ['D0', 'D1', 'D2']},
index=[ 'a','b','c'])
left.join(right, how='outer')
Out[30]:
A B C D
a A0 B0 NaN NaN
b A1 B1 NaN NaN
c NaN NaN C0 D0
d NaN NaN C1 D1上述的代码中首先创建了两个DataFrame类型的left对象与right对象,然后使用jion()方法将left对象与right对象进行合并,将right对象名做为参数传入,然后在使用how参数指定连接的方式,合并后缺失的数据使用NaN填充。
假设两个表中存在行索引与列索引重叠,那么当使用join()方法进行合并时,使用参数on指定重叠的列名即可。
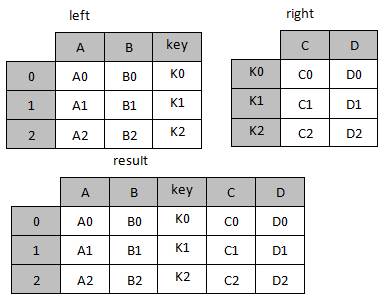
图2 合并示意图
如图2所示为合并后的效果,接下来,通过编写代码来实现上述效果,具体代码如下。
In [31]: import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2'],
'key': ['K0', 'K1', 'K2']})
right = pd.DataFrame({'C': ['C0', 'C1','C2'],'D': ['D0', 'D1','D2']},
index=['K0', 'K1','K2'])
# on参数指定连接的列名
left.join(right, how='left', on='key')
Out[31]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2在上述示例中,首先创建了两个DataFrame类型的left对象与right对象,然后在join()方法中设置连接方式与连接的列名。

隐藏目录