离散化连续数据
有时候我们会碰到这样的需求,例如,将有关年龄的数据进行离散化(分桶)或拆分为“面元”,直白来说,就是将年龄分成几个区间。 Pandas 的 cut ()函数能够实现离散化操作,该函数的语法格式如下:
pandas.cut(x,bins,right = True,labels = None,retbins = False,precision = 3,
include_lowest = False,duplicates ='raise' )上述函数中常用参数表示的含义如下:
(1) x:表示要分箱的数组,必须是一维的。
(2) bins:接收int和序列类型的数据。如果传入的是int类型的值,则表示在x范围内的等宽单元的数量(划分为多少个等间距区间);如果传入的是一个序列,则表示将x划分在指定的序列中,若不在此序列中,则为NaN。
(3) right:是否包含右端点,决定区间的开闭,默认为True。
(4) labels:用于生成区间的标签。
(5) retbins:是否返回bin。
(6) precision:精度,默认保留三位小数。
(7) include_lowest:是否包含左端点。
cut()函数会返回一个Categorical对象,我们可以将其看作一组表示面元名称的字符串,它包含了分组的数量以及不同分类的名称。
假设当前有一组年龄数据,需要将这组年龄数据划分为0-12岁、12-25岁、25-45岁、45-50岁、50岁以上共5种类型,图1是将这些数据经过面元划分后的对比效果。
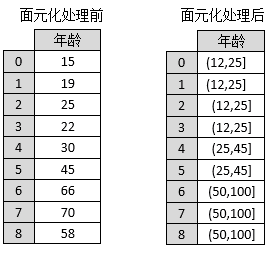
图1 面元化处理过程
接下来,我们通过一个示例来演示如何使用cut()函数将这组年龄数据进行面元划分,具体代码如下:
In [43]: import pandas as pd
# 使用pandas的cut函数划分年龄组
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 32]
bins = [0, 18, 25, 35, 60, 100]
cuts = pd.cut(ages, bins)
cuts
Out[43]:
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (35, 60],
(25, 35], (60, 100], (35, 60], (25, 35]]
Length: 11
Categories (5, interval[int64]): [(0, 18] < (18, 25] < (25, 35] < (35, 60) < (60, 100))上述代码中,定义了表示年龄数据集和划分规则的变量ages和bins,然后调用cut()函数将ages按照bins的划分规则进行分组。上述示例返回了一个Categories类对象,它包含了面元划分的个数以及各区间的范围。
Categories对象中的区间范围跟数学符号中的“区间”一样,都是用圆括号表示开区间,用方括号则表示闭区间。如果希望设置左闭右开区间,则可以在调用cut()函数时传入right=False进行修改,示例代码如下。
In [44]: pd.cut(ages, bins=bins, right=False)
Out[44]:
[[18, 25), [18, 25), [25, 35), [25, 35), [18, 25), ..., [35, 60), [25, 35),
[60, 100), [35, 60), [25, 35)]
Length: 11
Categories (5, interval[int64]): [[0, 18) < [18, 25) < [25, 35) < [35, 60) < [60, 100)]
隐藏目录