数据统计—滑动窗口
在时间序列中,还有另外一个比较重要的概念—滑动窗口。滑动窗口指的是根据指定的单位长度来框住时间序列,从而计算框内的统计指标。相当于一个长度指定的滑块在刻度尺上面滑动,每滑动一个单位即可反馈滑块内的数据。
滑动窗口的概念比较抽象,下面我们来举个例子描述一下。某分店按天统计了2017年全年(1月1日~12月31日)的销售数据,现在总经理想抽查分店8月28日(七夕)的销售情况,如果只是单独拎出来8月28日当天的数据,如图1所示,则这个数据比较绝对,无法很好地反映出这个日期前后销售的整体情况。

图1 时间序列中取单个值
为了提升数据的准确性,可以将某个点的取值扩大到包含这个点的一段区间,用区间内的数据进行判断。例如,我们可以将8月24日到9月2日的数据拿出来,求此区间的平均值作为抽查结果,示意图如图2所示。

图2 时间序列中一段区间
图2中的方块是一段区间,这个区间就是窗口,它的单位长度为10,数据是按天统计的,所以统计的是10天的平均指标。这样显得更加合理,可以很好地反映了七夕活动的整体情况。
移动窗口就是窗口向一端滑行,每次滑行并不是区间整块的滑行,而是一个单位一个单位的滑行。例如,把图2的窗口向右边滑行一个单位,此时窗口框住的时间区间范围为2017-08-25到2017-09-03,具体如图3所示。

图3 窗口向右滑行一个单位
每次窗口移动,一次只会移动一个单位的长度,并且窗口的长度始终为10个单位长度,直至移动到末端。由此可知,通过滑动窗口统计的指标会更加平稳一些,数据上下浮动的范围会比较小。
Pandas中提供了一个窗口方法rolling(),其语法格式如下:
rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0,
closed=None)部分参数含义如下:
(1) window:表示窗口的大小,值可以是int(整数值)或offset(偏移)。如果是整数值的话,每个窗口是固定的大小,即包含相同数量的观测值。如果值为offset,则指定了每个窗口包含的时间段,每个窗口包含的观测值的数量是不一定的。
(2) min_periods:每个窗口最少包含的观测值数量。值可以是int类型,则默认为None,值还可以是offset类型,则默认为1。
(3) center:是否把窗口的标签设置为居中,默认为False。
(4) win_type**:**表示窗口的类型。
(5) on:对于dataframe而言,指定要计算滚动窗口的列,值为列名。
(6) axis:默认为0,表示对列进行计算。
(7) closed:用于定义区间的开闭。
为了让读者更好地理解,接下来,我们通过一段示例程序来演示如何在时间窗口上应用mean()方法。首先,创建一组时间序列数据,示例代码如下。
In [52]: year_data = np.random.randn(365)
date_index = pd.date_range('2017-01-01', '2017-12-31', freq='D')
ser = pd.Series(year_data, date_index)
ser.head()
Out[52]:
2017-01-01 -1.652917
2017-01-02 -2.708868
2017-01-03 -0.325617
2017-01-04 1.068916
2017-01-05 0.989759
Freq: D, dtype: float64调用rolling()方法按指定的单位长度创建一个滑动窗口,示例代码如下。
In [53]: roll_window = ser.rolling(window=10)
roll_window
Out[53]:
Rolling [window=10, center=False, axis=0]上述示例返回了一个Rolling类对象,表示一个滑动窗口,它里面的window=10代表窗口的大小为10,center=False代表窗口的标签不居中,axis=0代表对列进行计算。窗口会按照从左向右的方向,一个单位一个单位的向右滑行。
如果要在窗口中统计一些指标,比如中位数、平均值等,则可以对窗口应用相应的统计方法。例如,在时间窗口中计算这一段数据的平均值,示例代码如下。
In [54]: roll_window.mean()
Out[54]:
2017-01-01 NaN
2017-01-02 NaN
2017-01-03 NaN
2017-01-04 NaN
2017-01-05 NaN
2017-01-06 NaN
2017-01-07 NaN
2017-01-08 NaN
2017-01-09 NaN
2017-01-10 -0.165571
2017-01-11 -0.083827
2017-01-12 0.413157
2017-01-13 0.506253
...
2017-12-29 -0.201605
2017-12-30 -0.111516
2017-12-31 0.090050
Freq: D, Length: 365, dtype: float64从输出结果中可以看出,由于前9个时间戳的单位长度小于10,所以返回的数据都为NaN,从第10个时间戳开始,所有时间戳对应的都是每个窗口的平均值。
为了更好地观测窗口的特点,接下来,使用matplotlib画图工具来展示原始数据与所有窗口中数据的区别,示例代码如下。
In [55]: import matplotlib.pyplot as plt
%matplotlib inline
ser.plot(style='y--')
ser_window = ser.rolling(window=10).mean()
ser_window.plot(style='b')
Out[55]:
<matplotlib.axes._subplots.AxesSubplot at 0x924a8d0>上述示例中,根据原始数据绘制了黄色、线型为虚线的折线,根据窗口中的数据绘制了深蓝色、线型为实线的折线。
运行结果如图4所示。
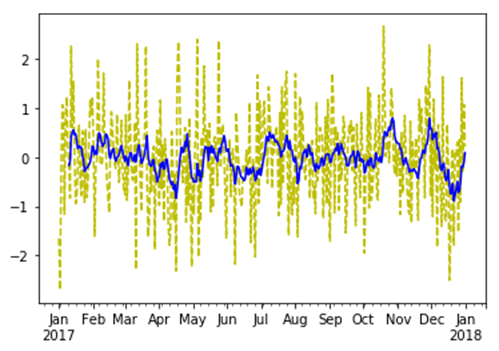
图4 运行结果
从图4的折线图中可以看出,由于随机数本身的特点,所有的数据浮动的幅度比较大,而窗口数据的整体动向相对趋于平稳。

隐藏目录