文本分类
文本分类是指按照一定的分类体系或标准,用电脑对文本集进行自动分类标记,主要的目的是将文本或文档自动地归类为一种或多种预定义的类别。通俗来说,就是拿一篇文章问计算机,这篇文章说的究竟是美食、体育还是政治,示意如图1所示。
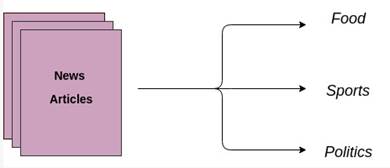
图1 文本分类示意图
以某新闻网站举例,它通常会把新闻划分为几种类型:体育类、科技类、娱乐类等,即给这些新闻先打上标签,如果某个用户经常阅读科技类的新闻,则可以把科技类的新闻推荐给该用户。
文本分类被广泛应用于解决各种商业领域的问题,常见应用包括:
理解社交媒体用户的情感。
识别垃圾邮件与正常邮件。
自动标注用户的查询。
将新闻按已有的主题分类。
文本分类属于有监督的机器学习,主要是因为文本分类可以利用一个包含文本/文档以及其对应类标的数据集,训练一个分类器。一般文本分类的实现包括以下步骤:
(1) 数据集准备:包括数据集以及基本的预处理工作,用于将原始语料格式化为同一格式,便于后续进行统一处理。
(2) 特征抽取:从文档中抽取出反映文档主题的特征。
(3) 模型训练:分类器模型会在一个有标注数据集上进行训练。
(4) 分类结果评价:分类器的测试结果分析。
为了能够让读者更好地理解文本分类,接下来通过一个判断人名性别的示例,按上述步骤使用NLTK库进行实现,具体内容如下。
在nltk.corpu语料库的names模块中存放着大量的英文人名信息,并且这些人名按照性别分成了两个文件:male.txt和female.txt,它们就是收集的样本,收集数据的代码如下。
In [37]: import nltk
from nltk.corpus import names
import random
# 收集数据,用一部分数据来训练,用一部分数据用来测试
names = [(name,'male') for name in names.words('male.txt')] \
+ [(name,'female') for name in names.words('female.txt')]
# 将names的所有元素随机排序
random.shuffle(names)
names
Out[37]:
[('Barr', 'male'), ('Bill', 'male'), ('Israel', 'male'),
('Kamila', 'female'), ('Berny', 'female'), ('Sean', 'female'),
('Claudetta', 'female'), ('Dita', 'female'), ...]从输出结果中可以看出,names序列中的人名不再是按照性别排序,而是随机排列的,因此每次输出的结果都是不一样的。
准备好样本数据以后,接下来是选取区分性别的特征。如何辨别一个人的名字是哪个性别呢?最简单的一种方式是根据最后两个字母进行判断,这种方式虽然并不是最为可靠的方式,但是可以作为性别区分的一种可能性特征。
定义一个选取特征的函数,接收一个人名,返回这个名字中最后两个字母。然后遍历names中的每个姓名和性别,将姓名的后两个字母与性别整合成一个特征集,具体代码如下。
In [38]: # 特征提取器
def gender_features(word):
# 特征就是最后一个字母和倒数第二个字母
return {'最后一个字母':word[-1],'倒数第二个字母':word[-2]}
features = [(gender_features(n),g) for (n,g) in names]
features
Out[38]:
[({'最后一个字母': 'r', '倒数第二个字母': 'r'}, 'male'),
({'最后一个字母': 'l', '倒数第二个字母': 'l'}, 'male'),
({'最后一个字母': 'l', '倒数第二个字母': 'e'}, 'male'),
({'最后一个字母': 'o', '倒数第二个字母': 'd'}, 'male'),
({'最后一个字母': 'a', '倒数第二个字母': 't'}, 'female'),
({'最后一个字母': 'a', '倒数第二个字母': 'r'}, 'female'),
({'最后一个字母': 'e', '倒数第二个字母': 'n'}, 'female'),
({'最后一个字母': 'n', '倒数第二个字母': 'a'}, 'female'),
({'最后一个字母': 'a', '倒数第二个字母': 't'}, 'female'),
({'最后一个字母': 'a', '倒数第二个字母': 't'}, 'female'),
...]应用模型算法对数据进行训练,以得出相应算法的模型,这里选择的是朴素贝叶斯算法,前面我们也有所介绍,它主要的原理是采用最大可能性进行结果的选取。
通常在数据收集时,会分成两部分,一部分用来训练,一部分用来测试,测试的数据用来得出模型的准确率。接下来,从特征数据集features中选取前500个数据作为训练集,再选择后500个数据作为测试集,具体代码如下。
In [39]: train, test = features[500:],features[:500]
# 使用训练集训练模型
classifier = nltk.NaiveBayesClassifier.train(train) 最后一步就是测试模型,进而判断选取的特征是不是合理,是不是有效,测试的代码如下。
In [41]: # 通过测试集来估计分类器的准确性
nltk.classify.accuracy(classifier, test)
Out[41]: 0.778
In [43]: # 如果一个人的名字是‘Ella,那么这个人是男还是女
classifier.classify({'last_letter': 'Ella'})
Out[43]: 'female'
In [44]: # 检查分类器,找出最能够区分名字性别的特征值
classifier.show_most_informative_features(5)
Out[44]:
Most Informative Features
最后一个字母 = 'a' female : male = 37.1 : 1.0
最后一个字母 = 'k' male : female = 30.6 : 1.0
最后一个字母 = 'f' male : female = 17.2 : 1.0
最后一个字母 = 'p' male : female = 11.8 : 1.0
最后一个字母 = 'v' male : female = 10.5 : 1.0多学一招:TF-IDF算法
如果某个词或短语在一篇文章中出现的频率很高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。通过计算词语的权重,可以找出文档中的关键词,从而确定分类的依据。常用的词语权重计算方法为TF-IDF算法。
TF-IDF算法的公式如下:
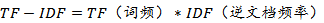
词频TF的计算公式如下:
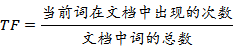
逆文档频率IDF的计算公式如下:
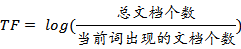
例如,一个文档中一共有100个单词,其中单词flower出现的次数为5,则TF=5/100,结果为0.05。样本中一共有10000000个文档,其中出现单词flower的文档有1000个,则IDF=log(10000000/1000),结果为4。因此,flower的TF-IDF值为:TF-IDF=TF*IDF=0.05*4=0.2。
若TF-IDF值越大,则说明这个词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
nltk.text模块中提供了TextCollection类来表示一组文本,它可以加载文本列表,或者包含一个或多个文本语料库,并且支持计数、协调、配置等等,例如创建一个TextCollection实例,代码如下。
import nltk.corpus
from nltk.text import TextCollection
# 首先,把所有的文档放到TextCollection类中
# 这个类会自动断句,做统计,做计算
corpus = TextCollection(['this is sentence one',
'this is sentence two',
'this is sentence three'])如果想知道某个单词在文本中的权重,则需要调用tf_idf()方法实现,该方法会返回一个tf_idf值,示例代码如下。
# 直接就能算出tf_idf
corpus.tf_idf('this', 'this is sentence four')
# 返回结果为
0.01930786229086497
隐藏目录