链式存储的实现
链表的几种操作与顺序表差不多,也是增删改查几种操作。接下来我们来实现一个链表。
1、创建链表
以图1为例,在创建链表时,头结点中保存链表的信息,则需要创建一个struct,在其中定义链表的信息与指向下一个结点的指针。代码如下:
struct Header //头结点
{
int length; //记录链表大小
struct Node* next; //指向第一个结点的指针
};存储元素的结点包含两部分内容:数据域和指针域,则也需要定义一个struct,代码如下:
struct Node //结点
{
int data; //数据域
struct Node* next; //指向下一个结点的指针
};这样头结点与数据结点均已定义。为了使用方便,将两个struct用typedef重新定义新的名称,代码如下:
typedef struct Node List; //将struct Node重命名为List
typedef struct Header pHead; //将struct Header重命名为pHead创建链表要比创建顺序表简单一些。顺序表中需要先为头结点分配空间,其次为数组分配一段连续空间,将这段连续空间地址保存在头结点中,然后往其中存储元素。但创建链表时,只需要创建一个头结点,每存储一个元素就分配一个存储单元,然后将存储单元的地址保存在上一个结点中即可,不需要在创建时把所有的空间都分配好。
创建链表的代码如下:
pHead * createList()//pHead是struct Header的别名,是头结点类型
{
pHead* ph = (pHead*)malloc(sizeof(pHead)); //为头结点分配内存
ph->length = 0; //为头结点初始化
ph->next = NULL;
return ph; //将头结点地址返回
}2、获取链表大小
链表的大小等信息也是保存在头结点中,因此需要时从头结点中获取即可,代码如下:
int Size(pHead* ph) //获取链表大小
{
if (ph == NULL)
{
printf("参数传入有误!");
return 0;
}
return ph->length;
}3、插入元素
在链表中插入元素时要比在顺序表中快。以图2-8为例,如果要在46和100之间插入元素99,其插入过程也较简单:首先将46和100之间的连接断开,然后46结点的指针指向99,将99结点的指针指向100,这样就完成了插入。其过程如图1所示。
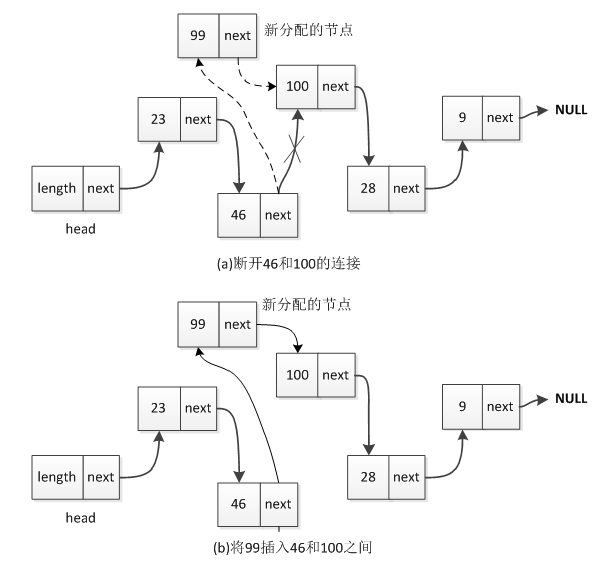
图1 在链表中插入新元素
在插入元素时,不必像顺序表中那样移动元素,效率要高很多。其代码实现如下:
int Insert(pHead* ph, int pos, int val) //在某一个位置插入某一个元素,插入成功返回1;
{
//先作健壮性判断
if (ph == NULL || pos < 0 || pos > ph->length)
{
printf("参数传入有误!");
return 0;
}
//在向链表中插入元素时,先要找到这个位置
List* pval = (List*)malloc(sizeof(List)); //先分配一块内存来存储要插入的数据
pval->data = val;
List *pCur = ph->next; //当前指针指向头结点后的第一个结点
if (pos == 0) //插入在第一个位置
{
ph->next = pval; //指针断开连接过程
pval->next = pCur;
}
else
{
for (int i = 1; i < pos; i++) //找到要插入的位置
{
pCur = pCur->next;
}
pval->next = pCur->next; //指针断开再连接过程
pCur->next = pval;
}
ph->length++; //增加一个元素,长度要加1
return 1;
}4、查找某个元素
查找链表中的某个元素,其效率没有顺序表高,因为不管查找的元素在哪个位置,都需要将它前面的元素都全部遍历才能找到它。查找的代码实现如下:
List* find(pHead* ph, int val) //查找某个元素
{
//先作健壮性判断
if (ph == NULL)
{
printf("参数传入有误!");
return NULL;
}
//遍历链表来查找元素
List *pTmp = ph->next;
do
{
if (pTmp->data == val)
{
return pTmp;
}
pTmp = pTmp->next;
} while (pTmp->next != NULL); //循环条件是直到链表结尾
printf("没有值为%d的元素!", val);
return NULL;
}5、删除元素
在删除元素时,首先将被删除元素与上下结点之间的连接断开,然后将这两个上下结点重新连接,这样元素就从链表中成功删除了。例如,将图1(b)中的元素28删除,其过程如图2所示。
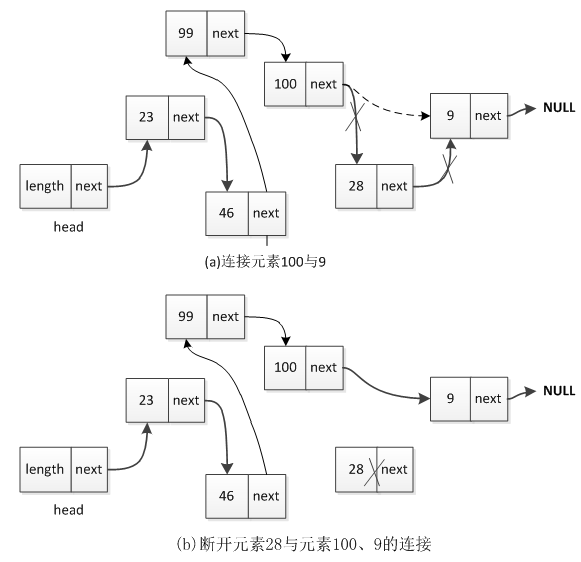
图2 从链表中删除元素
从链表中删除元素,也不需要移动其他元素,效率也较高。其代码实现如下:
List* Delete(pHead* ph, int val) //删除值为val的元素,删除成功,返回删除的元素
{
//先作健壮性判断
if (ph == NULL)
{
printf("链表传入错误!");
return NULL;
}
//找到val值所在结点
List* pval = find(ph, val);
if (pval == NULL)
{
printf("没有值为%d的元素!", val);
return NULL;
}
//遍历链表去找到要删除结点,并找出其前驱及后继结点
List *pRe = ph->next; //当前结点
List *pCur = NULL;
if (pRe->data == val) //如果删除的是第一个结点
{
ph->next = pRe->next;
ph->length--;
return pRe;
}
else //如果删除的是其他结点
{
for (int i = 0; i < ph->length; i++) //遍历链表
{
pCur = pRe->next;
if (pCur->data == val) //找到要删除的元素
{
pRe->next = pCur->next; //将被删除元素的上下两个结点连接起来
ph->length--; //长度减1
return pCur; //将被删除的元素结点返回
}
pRe = pRe->next;
}
}
}6、销毁链表
销毁链表时,将链表中每个元素结点释放掉,可以将头结点释放掉;但也可以保留头结点,将其置于初始化状态。代码实现如下:
void Destory(pHead* ph) //销毁链表
{
List *pCur = ph->next;
List *pTmp;
if (ph == NULL)
printf("参数传入有误!");
while (pCur->next != NULL)
{
pTmp = pCur->next;
free(pCur); //将结点释放
pCur = pTmp;
}
ph->length = 0; //回到初始化状态
ph->next = NULL;
}在本例中,没有释放掉头结点,只是将头结点中的信息归于了初始化状态。
7、遍历打印链表
实现出链表的遍历打印函数,是为了在接下来的测试程序中避免代码重复,打印链表的代码如下:
void print(pHead *ph)
{
if (ph == NULL)
{
printf("参数传入有误!");
}
List *pTmp = ph->next;
while (pTmp != NULL)
{
printf("%d ", pTmp->data);
pTmp = pTmp->next;
}
printf("\n");
}至此,链表基本的操作都已经实现,接下来可以用测试程序来测试这个链表的使用情况。同样,由于上述操作函数都已经实现,在接下来的测试中只给出头文件list.h和测试代码文件main.c,而函数实现list.c,读者可以复制上述各操作函数的代码,也可以试着自己来实现。具体如例1所示。
例1
list.h //头文件
1 #ifndef _LIST_H_
2 #define _LIST_H_
3
4 struct Node;
5 typedef struct Node List;
6 typedef struct Header pHead;
7
8 pHead * createList(); //创建链表
9 int isEmpty(pHead* l); //判断链表是否为空
10 int Insert(pHead* l, int pos, int val); //插入元素,插入成功返回1;
11 List* Delete(pHead* l, int ele); //删除元素,删除成功,返回删除的元素
12 List* find(pHead* l, int ele); //查找某个元素是否存在
13 int Size(pHead* l); //获取链表大小
14 void Destory(pHead* l); //销毁链表
15 void print(pHead *l); //打印链表
16
17 struct Node //结点
18 {
19 int data; //数据域
20 struct Node* next; //指向下一个结点的指针
21 };
22
23 struct Header //头结点
24 {
25 int length; //记录链表大小
26 struct Node* next;
27 };
28 #endifmain.c //测试文件
29 #define _CRT_SECURE_NO_WARNINGS
30 #include "list.h"
31 #include <stdio.h>
32 #include <stdlib.h>
33
34 int main()
35 {
36 int ret;
37 pHead *ph = createList(); //创建链表
38 if (ph == NULL)
39 {
40 printf("创建链表失败!\n");
41 }
42 int arr[10] = { 1, 2, 3, 4, 56, 76, 7, 4, 36, 34 }; //定义一个int类型数组
43
44 for (int i = 0; i <= 6; i++)
45 {
46 Insert(ph, 0, arr[i]); //将数组元素插入到链表中,每次都从头部插入
47 }
48
49 printf("链表长度:%d\n", Size(ph));
50
51 printf("打印链表中的元素:\n");
52 print(ph);
53 printf("删除链表中的元素,请输入要删除的元素:\n");
54 int num;
55 scanf("%d", &num); //本例中为测试程序,为减少异常处理,请输入链表中有的元素
56 Delete(ph, num);
57 printf("元素删除成功,删除元素%d后,链表中元素为:\n", num);
58 print(ph);
59
60 ret = find(ph, 3); //查找链表中某一个元素
61 if (ret)
62 printf("get!\n");
63 else
64 printf("NO!\n");
65
66 system("pause");
67 return 0;
68 }运行如图3所示。
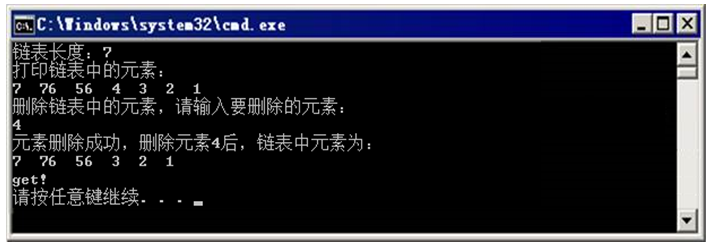
图3 例1运行结果
在例1中,第37行代码创建了一个链表;第42-47行定义了一个int类型数组,并将数组中的元素插入到了链表中;第49行代码打印出了链表的长度,由图2-11可知,链表长度为7;第52行代码调用print()函数遍历打印出了链表中的元素;第53-57行代码是删除链表中的某个元素,从键盘输入的元素为4,即删除链表中的元素4;第58行代码又调用print()函数重新打印删除4后的链表元素,由图2-11的运行结果可知,元素4删除成功;第60-64行代码是查找链表中是否有值为3的元素,由运行结果可知,这个元素存在。
至此,线性表的顺序存储与链式存储,包括其原理和实现方式都已讲解完毕,相信读者对这两种表也有了一定的掌握,其实只要理解了其存储原理,思路清晰,代码实现并不难。掌握了这两种最基本的线性表,对接下来其他数据结构的学习会有很大帮助。

隐藏目录