深度优先遍历
深度优先遍历(Depth First Search)是树先序遍历的推广,它的基本思想是:任意选定图中一个顶点v,从顶点v开始访问,然后选定v的一个没有被访问过的邻接点w,对顶点w进行深度优先遍历,直到图中与当前顶点邻接的顶点全部被访问为止。如果当前仍有顶点尚未访问,则从未访问的顶中任选一个顶点,执行前述遍历过程。显然这个遍历过程是一个递归的过程。
在树中讲解了四种遍历方法,根据不同的遍历方法可以获取唯一确定的路径。但是图中顶点的顺序是任意的,到达每个顶点的路径可能有多条,并且图中可能存在回路,在遍历的过程中一个顶点可能被重复访问多次。为了避免这个问题,我们设置一个数组来记录每个顶点的访问状态。
以顶点v为首,在遍历的过程中,设置下面两个辅助变量:①状态数组visited[]。这个数组用来记录每个顶点的状态,当顶点i被访问时,它的visited[i]状态从0修改为1,表示这个顶点已经被访问。②记录当前访问位置的栈stack[]。每访问一个顶点,就让顶点入栈。若遇到一个顶点,该顶点不存在未被访问的邻接点,则从栈中弹出一个顶点u,检查顶点u的邻接点是否被访问,并访问其中未被访问的顶点。当栈为空时,代表与顶点v连通的所有顶点遍历完毕。这个栈在递归过程中一直存在。
如果经过上述过程,图中所有顶点均已被访问,那么遍历结束。否则,要另选一个未被访问的顶点作为起点,重复上述过程,直到图中所有顶点都被访问为止。
以图1中的无向图G为例,举例说明图的遍历过程。为了陈述方便,在遍历过程中,若一个顶点有多个邻接点,优先选择靠左的邻接点。
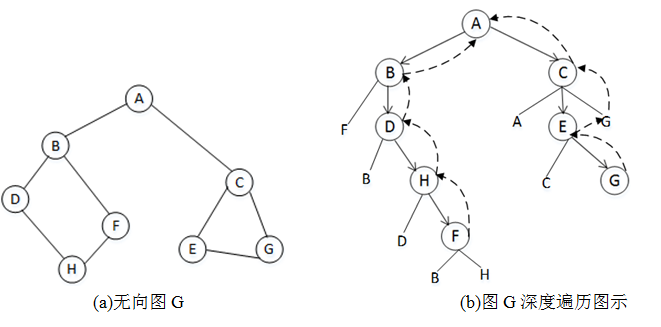
图1 深度优先遍历示例
参照图1(b)理解无向图的遍历。首先选定A作为第一个访问的顶点。在访问了顶点A后,选择靠左的顶点B,检测到顶点B尚未被访问;其次从顶点B出发进行搜索。之后依次选择顶点D、H、F进行访问。此时,栈stack中存储的元素从底到顶依次为:A、B、D、H、F,如图2(a)所示。

图2 栈stack
当F访问完毕时,本该去访问它的邻接点B和H,但是检测到B和H在状态数组visited[]中的状态均为已访问,于是将栈stack中的F弹出。检测之后的栈顶元素H,发现H的邻接点状态同样为已访问,于是将H弹出。继续检测栈顶数据,若栈顶的数据其邻接点为已访问,则弹出该元素,检查新的栈顶元素。
直到检测到栈底元素A,发现A有一个邻接点C未被访问,于是以C为顶点继续遍历,遍历的次序为C、E、G,并将这三个顶点依次入栈,此时栈中的元素为:A、C、E、G,如图7-16(b)所示。
遍历到顶点G时,发现其邻接点均已访问,弹出G并检测新的栈顶。直到栈为空,与A连通的所有顶点均已访问。
此时检查状态数组visited[],其中没有状态为0的顶点,表明图G中所有顶点均已被访问,图G遍历完毕。
图1中的图G为一个连通图,若非连通图,在一轮遍历结束之后,数组visited[]中应仍有状态为0的顶点,此时只需选取这些顶点中的一个,再次执行遍历步骤即可。
下面分别给出了以邻接矩阵存储图和以邻接表存储图时的深度优先递归算法。
//①基于邻接矩阵存储的深度优先递归算法
int visited[MAX_VERTEX_NUM] = { 0 }; //访问状态数组,初始化为0,表示未被访问
void DFS(Graph G, int i)
{
int j;
//将当前访问的顶点状态修改为1,表示已被访问
visited[i] = 1;
printf("%d ", G.vexs[i]); //打印顶点(或者需要的其它操作)
for (j = 0; j < G.n; j++)
{
//若该路径存在且邻接点j未被访问,则访问顶点j
if (G.edges[i][j] == 1 && visited[j] == 0)
DFS(G, j);
}
}
----------------------------------------------------------------------
//②基于邻接表存储的深度优先递归算法
int visited[MAX_VERTEX_NUM] = { 0 }; //访问状态数组,初始化为0,表示未被访问
void DFS(GraphAdjList GL, int i)
{
EdgeNode *p;
visited[i] = 1;
printf("%d ", GL.adjList[i].data); //打印顶点(或需要的其它操作)
p = GL.adjList[i].firstedge;
while (p)
{
if (!visited[p->adjvex])
DFS(GL, p->adjvex); //对未访问的邻接点进行递归调用
p = p->next;
}
}分析以上两个算法:两个算法大致相同,只因图的存储结构不同,所以在取值操作时有所差异。对于一个顶点数目为n,边数目为e的图:算法①中使用邻接矩阵存储图,在访问每个顶点的邻接点时,需要访问整个n阶邻接矩阵,所以其时间复杂度为O(n2);算法②中使用邻接表存储图,算法的时间复杂度只与其顶点数目n和边的数目e有关,是查找邻接点的时间复杂度O(n)与查找边的时间复杂度O(e)之和,为O(n+e)。
所以当对图进行遍历操作,且相对来说边数少于顶点数目时,使用邻接表存储可使代码运行效率得以提高。

隐藏目录