处理哈希冲突
哈希表好用,但也会有一些问题困扰,其中前面所讲的哈希冲突就是必须要处理的一个问题。
通过构造性能良好的哈希函数可以减少冲突,但一般不可能完全避免冲突,因此处理哈希冲突就成为了使用哈希表必须要面对的问题。在处理哈希冲突时,常用的方法有四种:开放定址法、再哈希法、拉链法、创建公共溢出区。接下来我们就分别来学习这几种处理冲突的方法。
1、开放定址法
开放定址法,其基本思想是:当关键字key的哈希地址p=f(key)出现冲突时,则以p为基础再产生另外一个哈希值p1=f(p),如果p1仍然冲突,再以p1为基础产生p2,如此操作直到产生一个不冲突的哈希地址pi,然后将相应元素存入其中。这种方法哈希函数如下所示:
fi(key) = (f(key)+di) % m; (di=1,2,3,…,n)其中m是哈希表长,di为增量序列,增量序列的取值不同,相应的定址方式也不同。
例如,现在有一组数据{107,8,13,22,16,30,103, 76,220,94},则要建立的哈希表长为10,哈希函数为f(key)=key%10。则这一组数据的哈希地址如下所示:
f(107)=107%10=7;
f(8)=8%10=8;
f(13)=13%10=3;
f(22)=22%10=2;
f(16)=16%10=6;
f(30)=30%10=0;
f(103)=103%10=3;
f(76)=76%10=6;
f(220)=220%10=0;
f(94)=94%10=4;将这组数据存储到哈希表中,前6个数据都没有问题,如表1所法。
表1 定址法创建哈希表
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 30 | 22 | 13 | 16 | 107 | 8 |
但是当存储103时,103哈希值为3,而角标3处已经存储了数据13,这就产生了冲突,那么利用上面的公式对103进行再散列,f2(103)=(f(103)+1)%10=4,于是将103存入角标为4的位置,如表2所示。
表2 存储103
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 30 | 22 | 13 | 103 | 16 | 107 | 8 |
接下来存储元素76,76的哈希值为6,而角标6处已经存储了数据16,则对76进行再散列,f2(76)=(f(76)+1)%10=7;但是角标7的位置也有数据107,因此第三次对76进行散列,f3(76)=(f2(76)+2)%10=8; 角标8处也有数据,那么对76进行第四次散列,f4(76)=(f3(76)+3)%10=9,角标9处没有数据,则将76存入角标9处。如表3所示。
表3 存储76
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 30 | 22 | 13 | 103 | 16 | 107 | 8 | 76 |
接下来存储元素220,则f(220)=220%10=0,因为角标0处已经有数据,则对220进行再散列,f2(220)=(f(220)+1)%10=1;角标1处没有数据,则将220存入角标1的位置处。如表4所示。
表4 存储220
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 30 | 220 | 22 | 13 | 103 | 16 | 107 | 8 | 76 |
接下来存储元素94,f(94)=94%10=4,角标4处有数据元素,则对94进行再散列,f2(94)=f(f(94)+1)%10=5;角标5处没有元素,则将94存入。如表5所示。
表5 存储94
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 30 | 220 | 22 | 13 | 103 | 94 | 16 | 107 | 8 | 76 |
至此,把这一组数据都存储到了哈希表中,这种解决冲突的方法就是开放定址法,因为di是线性增长的,所以也称为线性探测法。用线性探测法处理冲突,思路清晰、算法简单,但也会一些缺点,如处理溢出需要另外编写程序,删除工作比较困难等。
线性探测法很容易产生堆积现象,例如在存储元素76时,76和16、107、8这几个数据本来不是同义词,现在却需要争夺同一个地址,这种现象称为堆积。显然,堆积现象的出现需要不断的去处理更多的冲突,这使哈希表的存储查找效率大大降低。
仔细观察会发现,在存储76时,虽然角标6和后面的位置被占用,但前面的5是空闲的,那么是不是可以将76存储到5的位置呢,虽然经过不断的散列可以在后面找到空余位置,但效率太差。因此我们可以改进增量序列di的值,令di=12,-12,22,-22…q2,-q2,(q<=m/2),增加的平方运算是为了不让关键字聚集在某一块区域。这样就等于是可以在更大的范围内双向寻找可能的空位,例如用这种方法存储76时,取到-12时就找到了空闲位置5。
这种方法称为二次探测法,其哈希函数如下所示:
fi(key) = (f(key)+di) % m; (di=12,-12,22,-22…q2,-q2,(q<=m/2)) 相比于线性探测法,它减少了堆积现象的发生,而且不像线性探测法那样探查一个顺序的地址序列(相当于顺序查找),而是使探查序列跳跃式地分布在整个哈希表中。
除了上述两种探测方法外,还可以探测步长从常数改为随机数,即令di的值取一个随机数,其对应的哈希函数如下所示:
fi(key) = (f(key)+RN) % m; (RN是一个随机数) 在实际应用中,可以预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长,这样就能使不同的关键字具有不同的探测次序,从而避免或减少堆积。在查找时,使用同样的随机数发生器来查找关键字的存储位置。
在开放定址法的这三种处理方法中,如果要从哈希表中删除一个元素,不能仅仅将元素删除,将相应位置置空,而是要标记上已被删除的标记,否则会影响元素的查找。
2、再哈希法
所谓的再哈希法就是构造不同的哈希函数来求算不同关键字的哈希地址,例如第一个数据元素用直接定址法来求算哈希地址,第二个数据元素计算出来与第一个冲突了,那么就用平方取中法构造一个哈希函数来求算其哈希地址。这样每当有地址冲突时,就改用不同的哈希函数计算,最后总能解决掉冲突。这种方法能够使得关键字不产生堆积,但是相应地也增加了计算时间。
3、拉链法
拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中,若选定的哈希表长度为m,则可将哈希表定义为一个由m个头指针组成的指针数组T[0,m-1],凡是哈希地址为i(0<=i<=m-1)的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。
例如在开放定址法中所用的一组数据{107,8,13,22,16,30,103, 76,220,94},按照哈希函数f(key)=key%10,得出这一组数据的哈希地址为{7,8,3,2,6,0,3,6,0,4},则根据拉链法所创建的哈希表如图1所示。

图1 拉链法创建哈希表
在此哈希表中,互为同义词的数据元素都放在同一个单链表中,链表的地址存储在数组中,这
就是链表地址法的来源,通常称它为拉链法。
拉链法处理冲突简单且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短。由于链表上的结点空间是动态申请的,故它更适合于创建哈希表前不知道表长的情况。用拉链法创建哈希表,在表中删除结点的操作更易于实现,只要简单的删除链表上的相应结点即可。
当然它也有不足之处,指针需要额外的空间,故当结点规模较小时,拉链法并不是很好的一个选择,而且在查找时需要遍历单链表,有一定的性能损耗。
4、创建公共溢出区
创建公共溢出区也比较好理解,就是另外创建一个表专门用来存储产生冲突的数据元素,假如一个关键字计算出的哈希地址中已经有数据,那么就将这个关键字存储到溢出表中。例如图8-56中的一组数据,数据220,103,76都是与前面的元素有冲突的,那么就将它们存储到溢出区,如图2所示。
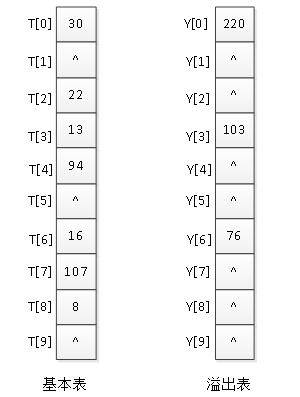
图2 建立公共溢出区
在查找时,对给定值通过哈希函数计算出哈希地址,先与基本的相应位置进行比对,如果相等
则查找成功;如果不相等,则到溢出表中进行顺序查找,如果找到,则查找成功,否则查找失败。相对于基本表而言,在有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是很高的。

隐藏目录