链式存储的原理
在链式存储中,结点之间的存储单元地址可能是不连续的。链式存储中每个结点都包含两个部分:存储元素本身的数据域和存储结点地址的指针域。在第一章中介绍链式存储时,讲解了一些链式存储的原理,结点中的指针指向的是下一个结点,如果结点中只有指向后继结点的指针,那么这些结点组成的链表称为单向链表。如图1所示,就是一个单链表。
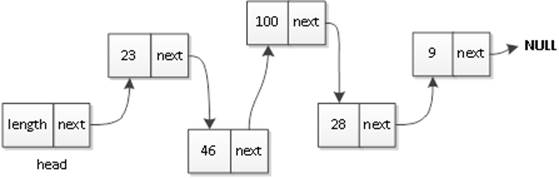
图1 单向链表
一般在链表中也会有一个头结点来保存链表的信息,然后有一个指针指向下一个结点,下一个结点又指向它后面的一个结点,这样直到最后一个结点,它没有后继结点,就指向NULL。
在链表中,这些存储单元可以是不连续的,因此它可以提高空间利用率,当需要存储元素时,哪里有空闲的空间就在哪里分配,只要将分配的空间地址保存到上一个结点就可以,这样通过访问前一个元素就能找到后一个元素。
当在链表中某一个位置插入元素时,从空闲空间中为该元素分配一个存储单元,然后将两个结点之间的指针断开,上一个结点的指针指向新分配的存储单元,新分配的结点中指针指向下一个结点;这样不需要移动原来元素的位置,效率比较高;同样,当删除链表中的某个元素时,就断开它与前后两个结点的指针,然后将它的前后两个结点连接起来,也不需要移动原来元素的位置。与顺序表相比较,在插入删除元素方面,链表的效率要比顺序表高许多。
但是随机查找元素时,链表没有索引标注,存储单元的空间并不连续,如果要查找某一个元素,必须先得经过它的上一个结点中的地址才能找到它,因此不管遍历哪一个元素,都必须把它前面的元素都遍历后才能找到它,效率就不如顺序表高。

点击此处
隐藏目录
隐藏目录